Routine and background tasks. Routine and background tasks Create a routine task in 1s 8.2
Asynchronous programming concept
The asynchronous programming concept is that the result of a function is not immediately available, but after some time in the form of some asynchronous (violating the normal order of execution) call.
Those. The main idea of asynchronous programming is to issue individual method calls and continue doing other work in parallel without waiting for the calls to finish.
Some methods that minimize the likelihood of exceptions do not require an asynchronous approach, but others require it at the very beginning of development.
As can be seen from the graphs, there is no coefficient of useful interactive user actions with a synchronous programming model, since the system blocks the user interface, while with an asynchronous model, the user continues to actively work in the system.

When running synchronously, the application has only one thread. With the asynchronous programming model, you can run multiple threads in parallel and react to new user actions as they run. Once the n-thread is executed, you display the result on the screen.
Background tasks in 1C:Enterprise 8
In 1C:Enterprise 8, background jobs are designed to perform application tasks asynchronously. They can generate child background jobs, for example, to parallelize complex calculations across different working servers of the cluster in a client-server mode of operation.
It is possible to restrict the execution of background jobs that have the same methods based on a specific application criterion. Programmatic creation and management of background jobs is possible from any user connection to the system information base. The background job runs on behalf of the user who created it.
The task mechanism functions in both the client-server and file modes of operation, but the capabilities for administering and executing tasks in both versions are somewhat different.
Client-server option
In the client-server version, task scheduling is carried out by the task scheduler, which is physically located in the cluster manager.
The scheduler periodically checks to see if any requests have been received to run background jobs. If there are jobs that need to be executed, the scheduler determines the least loaded worker processes in the cluster and sequentially assigns each of them its task to execute. Thus, the same worker process can potentially execute multiple jobs in parallel. After a job is received by a worker process, the worker process establishes a connection to the infobase and executes the job within that connection. After the job completes, the worker process notifies the scheduler whether the job completed successfully or unsuccessfully.
File option
Starting with version 8.3.3.641 of the platform, the developers have significantly simplified the work with background jobs in the file version.
Previously, to automatically execute tasks, it was necessary to launch a separate, additional 1C:Enterprise session, used as a task scheduler. And in this session it was necessary to periodically execute the built-in language method ExecuteTaskProcessing(). This approach was quite cumbersome, inconvenient and greatly limited the use of background and routine tasks in the file version of work.
Now everything has become much easier. If a thin or thick client starts, and also if the web server has client connections, then in each of these applications another thread is automatically launched with a connection to the database. These threads are engaged in performing background and routine tasks.
Each of the listed applications performs its own background tasks. If an application has initiated several background jobs, they are executed sequentially, in the order they were received.
The obvious disadvantage of 1C background jobs: since they are executed on the server side, there is no possibility of interactive work with the user (for example, it is impossible to display a message or some other information; all this data must be stored within the information base and further processed in some way).
It should be noted that background jobs are purely software objects and cannot be stored in the database. That is, we can only create an instance of a class, initialize its properties and launch it for execution.
An example of asynchronous code execution in 1C:Enterprise 8
“Writing programs in which the result of a function call arrives unknown when is much more difficult than ordinary ones. Nested calls, error handling, control over what is happening - everything becomes more complicated,” only those who do not know how to properly use the platform’s capabilities will say this, but not us!
Let's demonstrate the simplicity and elegance of asynchronous code execution in 1C:Enterprise 8!
Step 1. Let's create a new information security system for configuration development
Step 2. In the configuration we will add the general module “Asynchronous Handlers”
Why did we add a shared module? Everything is simple here: to perform asynchronous operations in 1C:Enterprise 8, background jobs are used, which have their own manager - “BackgroundTask Manager”. This object has a “Run” method, with the help of which the background task is launched.
Let's turn to the syntax assistant.

So we will need a common module.

Step 3. In the general module “Asyncronous Handlers” we will add the export procedure OurLongOperation()
Procedure OurLongOperation(Duration) Export // Simulation of a long-term action (Duration sec.).< Длительность Цикл КонецЦикла; КонецПроцедуры
OperationStartDate = CurrentDate(); While CurrentDate() - Operation Start Date

Step 4.
Add “Asynchronous Programming Concept” processing to the configuration (you can create external processing)
Add one attribute to the form:
Duration (Number)
and two teams
Perform LongOperation; Perform a Long-Long Operation Asynchronously.
Step 5.
According to the syntax assistant, fill out the form module&On the Client Procedure Perform Long-RunningOperation(Command) ExecuteLong-RunningOperationOnServer(); EndProcedure &OnServer Procedure ExecuteLongOperationOnServer() AsynchronousHandlers.OurLongOperation(Duration); End of Procedure &On the Client Procedure Perform Long-running Operation Asynchronously (Command) Perform Long-running Operation Asynchronously on Server (); End of Procedure &On the Server Procedure Perform Long-running Operation Asynchronously On the Server() Parameters = New Array;
Parameters.Add(Duration);
BackgroundTasks.Execute("AsynchronousHandlers.OurLongOperation", Parameters, New UniqueIdentifier, "Example of asynchronous programming concept"); EndProcedure
Step 6.
We can verify that the program code is executed asynchronously by looking at the log.

We can debug program code that runs in the “background” if we set the appropriate property in the debugging parameters.

An example of asynchronous code execution in 1C:Enterprise 8 using BSP
Let's consider an example of the implementation of the asynchronous programming concept in 1C:Enterprise 8 in the BSP using the example of processing “Current Affairs”.
The logic is as follows: when the program is launched, the work area of the start page is initialized, where the “Current Affairs” processing form can be displayed. This form is filled out by the user's current affairs, and it takes time to fill it out. If developers did not have the ability to execute code asynchronously, then the user interface would be blocked while the processing form was being filled out!

Let's analyze the program code of the form.
The form event “When CreatedOnServer” calls the “RunBackgroundTask” procedure - this is what we need.

Without being distracted by the nuances, let’s analyze this procedure

And here we see that the background job manager and its “Run” method are used. Note that developers store a unique ID for the background job.
To do this, developers use the method ConnectWaitHandler(<ИмяПроцедуры>, <Интервал>, <Однократно>).
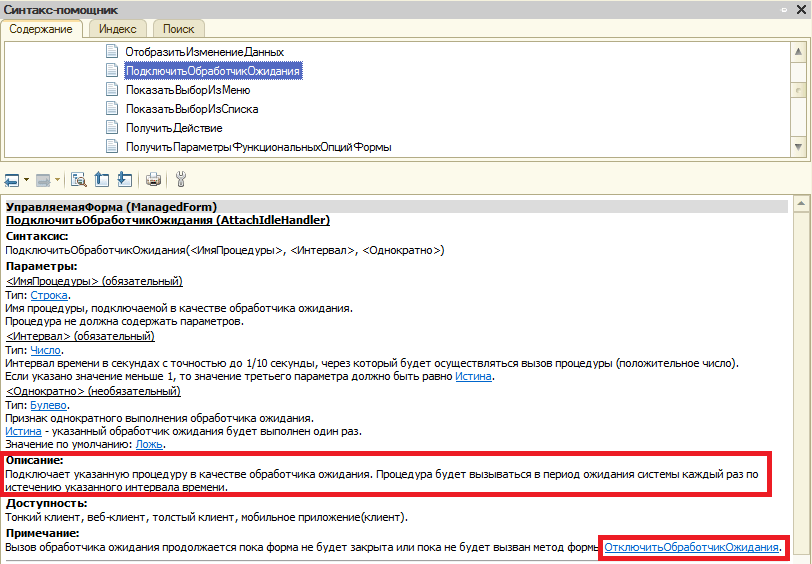

In a connected procedure Connectable_CheckTaskComplete() developers call the function JobCompleted(TaskID)

This function checks the execution of a background job by identifier.
It should be noted that the BSP has developed general modules to support long-term server operations.


Thus, the asynchronous programming concept in 1C:Enterprise 8 slightly increases the complexity of solving problems for the developer, but significantly improves the functionality of the program from the user’s point of view.
How to speed up work in 1C: Accounting 8.3 (edition 3.0) or disable routine and background tasks
2019-01-15T13:28:19+00:00Those of you who have already switched to the new edition of 1C: Accounting 8.3 (edition 3.0) have noticed that it has become slower than 2. Some strange slowdowns, endless background tasks several times a day, which no one asked her to perform without our knowledge.
My accountants told me immediately after the transition that the new edition of 1C: Accounting 3.0 is downright slow compared to the previous ones! And it’s simply impossible to work.
I started looking into it and very soon found out that the main cause of freezes and subsequent user dissatisfaction are routine and background tasks, many of which are enabled by default, although for the vast majority of accountants there is no need for them.
Well, for example, why do we need to run the “Text Extraction” task a hundred times a day if we do not carry out a full-text (accountants, don’t be alarmed) search across all objects in our database.
Or why constantly download currency rates if we do not have currency transactions or we do them occasionally (and before that we ourselves can click the download rates button).
The same applies to 1C’s constant attempt to connect to the site and check and update bank classifiers. For what? I myself will press the button to update the classifiers if I don’t find the right bank by its BIC.
How to do this step by step below.
1. Go to the "Administration" section and select "Maintenance" () in the action panel:
2. In the window that opens, find and select “Routine and background tasks”:

3. Open each task that has "On" in the "On" column. there is a daw.

4. Uncheck "Enabled" and click the "Save and Close" button.

5. Do this with each of the included tasks and enjoy the new edition. Overall, in my opinion, it is much better than two.
At the same time, the platform will still enable some of the scheduled tasks you disabled.
Probably every 1C 8.3 programmer sooner or later had to configure the execution of certain tasks on a schedule. Below I will give a detailed description of these mechanisms, I hope this will be useful information for novice 1C programmers. This is very convenient, because it does not require human action, the routine task is configured once and works according to your schedule.
You will find detailed instructions using an example below.
What are routine and background tasks in 1C
- Scheduled tasks is a special 1C Enterprise 8.3 mechanism designed to perform a specific action according to a given schedule.
- Background job- objects generated by a routine task that directly perform the intended action without the participation of the user or 1C 8.2 programmer.
The mechanism of scheduled and background jobs works in client-server mode (SQL), thanks to the functionality of the DBMS. If you have a file database, then the task can also be configured, but according to a slightly different principle.
Setting up background jobs in 1C client-server mode
First, let's create a new metadata object - a routine task. I will call my task “Loading Currency Rates”. Let's look at the properties palette of this configuration object:

Get 267 video lessons on 1C for free:
- Method name— path to the procedure that will be executed in a background job according to a given schedule. The procedure must be in a common module. It is recommended not to use standard ones, but to create your own. Don't forget that background jobs run on the server!
- Usage— a sign of using a routine task.
- Predetermined— indicates whether the routine task is predetermined. If you want the routine task to work immediately after being placed in the database, specify this flag. Otherwise, you will need to use Job Console processing or cause the job to run programmatically.
- Number of retries when a job terminates abnormally— how many times the background job was restarted if it was executed with an error.
- Retry interval when job terminates abnormally— how often the background job will be restarted if it was completed with an error.
And the most interesting setting is Schedule:

Here you configure the launch interval of the procedure specified in the “Method name” field. Let's say I configured
Attention! Don't forget to disable blocking the execution of routine and background jobs at the DBMS level!
This can be done in the administration utility of the client-server version or when creating a new database:

Setting up routine tasks in 1C file mode
In file mode, setting up such jobs is somewhat more difficult. For such a task, a separate session of the 1C program must be launched. This is often solved by creating a “technical” user whose session is always running.
In file mode, a routine job is initialized when the “RunTaskProcessing()” method is launched.
For a specific user, you can configure this method to run using another method −
ConnectWaitHandler( <ИмяПроцедуры>, <Интервал>, <Однократно>).
- Procedure name— the name of the procedure connected as a wait handler. The name of the exported procedure of a managed application module (a regular application module) or a global shared module. The procedure must be located on the client.
- Interval— period between executions of operations in seconds.
- One time- how to complete the task, once or not.
ConnectWaitHandler, 3600 ) ;
A two-minute video that shows how to set up a routine task in the 1C configurator:
When working in 1C, there are many routine operations that must be launched or formed according to a schedule to perform one or another action, for example: posting documents or loading data into 1C from a website.
I recently posted an article: It's time to automate this:
Routine and background tasks
The job engine is designed to perform any application or functionality on a schedule or asynchronously.
The task mechanism solves the following problems:
- Ability to define regulatory procedures at the system configuration stage;
- Execution of specified actions according to schedule;
- Making a call to a given procedure or function asynchronously, i.e. without waiting for its completion;
- Tracking the progress of a specific task and obtaining its completion status (a value indicating whether it was successful or not);
- Obtaining a list of current tasks;
- Ability to wait for one or more tasks to complete;
- Job management (possibility of cancellation, blocking of execution, etc.).
The job mechanism consists of the following components:
- Metadata of routine tasks;
- Regular tasks;
- Background jobs;
- Task Scheduler.
Background jobs & are designed to perform application tasks asynchronously. Background tasks are implemented using the built-in language.
Scheduled tasks & are designed to perform application tasks on a schedule. Routine tasks are stored in the information base and are created based on metadata defined in the configuration. Metadata of a regulatory task contains information such as name, method, use, etc.
A routine task has a schedule that determines at what times the method associated with the routine task must be executed. The schedule, as a rule, is specified in the information base, but can also be specified at the configuration stage (for example, for predefined routine tasks).
The task scheduler is used to schedule the execution of routine tasks. For each scheduled job, the scheduler periodically checks whether the current date and time matches the schedule of the scheduled job. If it matches, the scheduler assigns that task to execution. To do this, for this scheduled task, the scheduler creates a background task, which performs the actual processing.
I think that’s enough with the description - let’s get down to implementation:
Creating a routine task
Method name– path to the procedure that will be executed in a background job according to a given schedule. The procedure must be in a common module. It is recommended not to use standard common modules, but to create your own. Don't forget that background jobs run on the server!
Usage– sign of using a routine task.
Predetermined– indicates whether the routine task is predetermined.
If you want the routine task to work immediately after being placed in the database, specify the attribute Predetermined. Otherwise, you will need to use the “Job Console” processing or trigger the task to run programmatically.
Number of retries when a job terminates abnormally– how many times the background job was restarted if it was executed with an error.
Retry interval when job terminates abnormally– how often the background job will be restarted if it was completed with an error.
Setting up a schedule
Schedule completing the task:
| Every hour, just one day | RepeatDays Period = 0, RepeatDays Period = 3600 |
| Every day once a day | RepeatDays Period = 1, RepeatDays Period = 0 |
| One day, one time | PeriodRepeatDays = 0 |
| Every other day once a day | PeriodRepeatDays = 2 |
| Every hour from 01.00 to 07.00 every day | PeriodRepeatDays = 1RepeatPeriodDuringDay = 3600StartTime = 01.00 End Time = 07.00 |
| Every Saturday and Sunday at 09.00 | RepeatDays Period = 1WeekDays = 6, 7StartTime = 09.00 |
| Every day for one week, skip a week | PeriodRepeatDays = 1PeriodWeeks = 2 |
| At 01.00 once | Start Time = 01.00 |
| Last day of every month at 9:00. | PeriodRepeatDays = 1DayInMonth = -1StartTime = 09.00 |
| Fifth day of every month at 9:00 | PeriodRepeatDays = 1DayInMonth = 5StartTime = 09.00 |
| Second Wednesday of every month at 9:00 | PeriodRepeatDays = 1DayWeekMonth = 2DaysWeek = 3 Start Time = 09.00 |
Features of executing background jobs in file and client-server variants
The mechanisms for executing background jobs in the file and client-server versions are different.
In file version you need to create a dedicated client process that will perform background jobs. To do this, the client process must periodically call the global context function ExecuteJobProcessing. Only one client process per infobase should process background jobs (and, accordingly, call this function). If a client process has not been created to process background jobs, then when programmatically accessing the job engine, the error “Job Manager is not active” will be displayed. It is not recommended to use a client process that processes background jobs for other functions.
Once the client process processing background jobs is started, other client processes are able to programmatically access the background job engine, i.e. can run and manage background jobs.
In client-server version To execute background jobs, a task scheduler is used, which is physically located in the cluster manager. For all queued background jobs, the scheduler gets the least loaded worker process and uses it to run the corresponding background job. The worker process executes the job and notifies the scheduler of the execution results.
In the client-server version, it is possible to block the execution of routine tasks. The execution of routine tasks is blocked in the following cases:
- An explicit blocking of routine tasks has been installed on the information base. The lock can be set via the cluster console;
- There is a connection block on the infobase. The lock can be set via the cluster console;
- The SetExclusiveMode() method with the True parameter was called from the built-in language;
- In some other cases (for example, when updating the database configuration).
Processing the launch and viewing of scheduled tasks you can download here.
This article provides an example of working with background jobs, as in 1C background jobs are launched, how can you get a list of tasks using the method "GetBackgroundTasks()". So, this method returns us some array. Let's see what it contains.
Let me make a reservation right away that the example given was developed in the client-server version of the database.
The figure presented above shows the contents of this array.
Pay attention to the field "State". It contains information about whether the running background job has completed successfully or is still running.
It also contains information about the unsuccessful completion of the task. This array also contains information about keys, unique identifiers, and the name of background jobs. Information about running and completed tasks is stored in the infobase, but there is a limit on the number of records stored in the table. This number is about 1000 records. That is, when new elements are added, old ones are removed. Also, a task is deleted from the table if it was completed more than a day ago.
An example of working with a background job 1C - Method "GetBackgroundTasks"
Let's also look at working with background jobs using the method example "GetBackgroundTasks()". In this method, it is possible to set a selection for the received records. That is, we need to pass a structure as a method parameter.
The structure may contain fields: Unique identifier, Key, Status, Start, End, Name, MethodName, ScheduledTask.
For example, if we needed only running jobs, we would apply a selection with the name of the structure element “State” and the value, we would specify the system enumeration “BackgroundTask State” in the active state. So, first you need to ensure that records about the execution of 1C background tasks appear in the demo database.
To implement the example, we will do the following:
1. Let's create a common module "BackgroundTask Handlers" executing on the server.

And add the following code to it:
Procedure ProduceBackgroundCalculation(Parameter) ExportTimeStart = CurrentDate() ;
While CurrentDate() - Start Time Cycle
EndCycle ;
EndProcedure2. Let’s create a processing and place a button on the form "Run the task in the background" and in the procedure for processing the button click event, add the following code:
&On the Client Procedure ExecuteTask(Command) ExecuteBackgroundTaskOnServer() ;
EndProcedure
Description of the called procedure: &OnServer Procedure ExecuteBackgroundTaskOnServer()BackgroundTask Parameters = New Array; BackgroundTask Parameters. Add("Some parameter" &OnServer Procedure ExecuteBackgroundTaskOnServer()BackgroundTask Parameters = New Array;"Test" ) ; BackgroundTaskParameters = New Array; BackgroundTask Parameters. Add() ; BackgroundTasks. Run (
Now let's launch 1C in enterprise mode and start executing a background job.

Ready. By these actions, we ensured that records about the execution of 1C background jobs appeared in our demo database, and now we can demonstrate an example of obtaining their array contained in our database.
Let's add another button to the form "Get background jobs". Let's write the following code in the click processing procedure:
&On the Client Procedure GetBackgroundJob(Command) GetBackgroundJobOnServer() ;
EndProcedure
The text of the procedure on the server: BackgroundTask Parameters. Add(&OnServer Procedure GetBackgroundTasksOnServer() Selection Parameters = New Structure("Name" , ) ;
ListBackgroundTasks = BackgroundTasks. GetBackgroundTasks(SelectionParameters) ; "Get background jobs".





