Τα πάντα για τα ρομπότ. Ρομπότ Yandex
Γειά σου! Υπήρξε μια περίοδος στη ζωή μου που δεν ήξερα απολύτως τίποτα για τη δημιουργία ιστοσελίδων και σίγουρα δεν είχα ιδέα για την ύπαρξη του αρχείου robots.txt.
Όταν ένα απλό ενδιαφέρον εξελίχθηκε σε ένα σοβαρό χόμπι, εμφανίστηκε η δύναμη και η επιθυμία να μελετηθούν όλες οι περιπλοκές. Στα φόρουμ μπορείτε να βρείτε πολλά θέματα που σχετίζονται με αυτό το αρχείο, γιατί; Είναι απλό: το robots.txt ρυθμίζει την πρόσβαση των μηχανών αναζήτησης στον ιστότοπο, διαχειρίζεται την ευρετηρίαση και αυτό είναι πολύ σημαντικό!
Robots.txtείναι ένα αρχείο κειμένου που έχει σχεδιαστεί για να περιορίζει την πρόσβαση των ρομπότ αναζήτησης σε ενότητες και σελίδες του ιστότοπου που πρέπει να εξαιρεθούν από την ανίχνευση και τα αποτελέσματα αναζήτησης.
Γιατί να αποκρύψετε συγκεκριμένο περιεχόμενο ιστότοπου; Είναι απίθανο να είστε ευχαριστημένοι εάν ένα ρομπότ αναζήτησης ευρετηριάζει αρχεία διαχείρισης ιστότοπου, τα οποία μπορεί να περιέχουν κωδικούς πρόσβασης ή άλλες ευαίσθητες πληροφορίες.
Υπάρχουν διάφορες οδηγίες για τη ρύθμιση της πρόσβασης:
- User-agent - παράγοντας χρήστη για τον οποίο καθορίζονται κανόνες πρόσβασης,
- Απαγόρευση - αρνείται την πρόσβαση στη διεύθυνση URL,
- Να επιτρέπεται - επιτρέπει την πρόσβαση στη διεύθυνση URL,
- Χάρτης ιστότοπου - υποδεικνύει τη διαδρομή προς,
- Καθυστέρηση ανίχνευσης - ορίζει το διάστημα ανίχνευσης διεύθυνσης URL (μόνο για το Yandex),
- Clean-param - αγνοεί τις παραμέτρους δυναμικής διεύθυνσης URL (μόνο για το Yandex),
- Host - υποδεικνύει τον κύριο καθρέφτη του ιστότοπου (μόνο για το Yandex).
Λάβετε υπόψη ότι από τις 20 Μαρτίου 2018, η Yandex σταμάτησε επίσημα να υποστηρίζει την οδηγία Host. Μπορεί να αφαιρεθεί από το robots.txt και αν αφεθεί, το ρομπότ απλώς θα το αγνοήσει.
Το αρχείο πρέπει να βρίσκεται στον ριζικό κατάλογο του ιστότοπου. Εάν ο ιστότοπος έχει υποτομείς, τότε το δικό του robots.txt μεταγλωττίζεται για κάθε υποτομέα.
Πρέπει πάντα να θυμάστε την ασφάλεια. Αυτό το αρχείο μπορεί να προβληθεί από οποιονδήποτε, επομένως δεν χρειάζεται να καθορίσετε μια ρητή διαδρομή προς διαχειριστικούς πόρους (πίνακες ελέγχου κ.λπ.) σε αυτό. Όπως λένε, όσο λιγότερα ξέρεις, τόσο καλύτερα κοιμάσαι. Επομένως, εάν δεν υπάρχουν σύνδεσμοι σε μια σελίδα και δεν θέλετε να την καταχωρήσετε σε ευρετήριο, τότε δεν χρειάζεται να την καταχωρήσετε σε ρομπότ, κανείς δεν θα τη βρει έτσι κι αλλιώς, ούτε καν τα ρομπότ αράχνη.
Όταν ένα ρομπότ αναζήτησης ανιχνεύει έναν ιστότοπο, πρώτα ελέγχει για την παρουσία του αρχείου robots.txt στον ιστότοπο και, στη συνέχεια, ακολουθεί τις οδηγίες του κατά την ανίχνευση σελίδων.
Θα ήθελα να σημειώσω αμέσως ότι οι μηχανές αναζήτησης αντιμετωπίζουν αυτό το αρχείο διαφορετικά. Για παράδειγμα, το Yandex ακολουθεί άνευ όρων τους κανόνες του και αποκλείει απαγορευμένες σελίδες από την ευρετηρίαση, ενώ η Google αντιλαμβάνεται αυτό το αρχείο ως σύσταση και τίποτα περισσότερο.
Για να απαγορεύσετε την ευρετηρίαση σελίδων, μπορείτε να χρησιμοποιήσετε άλλα μέσα:
- ανακατεύθυνση ή σε έναν κατάλογο χρησιμοποιώντας το αρχείο .htaccess,
- noindex meta tag (δεν πρέπει να συγχέεται με το
- χαρακτηριστικό για συνδέσμους, καθώς και την αφαίρεση συνδέσμων σε περιττές σελίδες.
Σε αυτήν την περίπτωση, η Google μπορεί να προσθέσει με επιτυχία Αποτελέσματα αναζήτησηςσελίδες που απαγορεύεται η δημιουργία ευρετηρίου, παρά όλους τους περιορισμούς. Το κύριο επιχείρημά του είναι ότι εάν μια σελίδα συνδέεται με, τότε μπορεί να εμφανιστεί στα αποτελέσματα αναζήτησης. Σε αυτήν την περίπτωση, συνιστάται να μην συνδέεστε με τέτοιες σελίδες, αλλά με συγχωρείτε, το αρχείο robots.txt έχει ακριβώς σκοπό να εξαιρέσει τέτοιες σελίδες από τα αποτελέσματα αναζήτησης... Κατά τη γνώμη μου, δεν υπάρχει λογική 🙄
Αφαίρεση σελίδων από την αναζήτηση
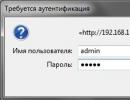
Εάν οι απαγορευμένες σελίδες εξακολουθούν να είναι ευρετηριασμένες, τότε πρέπει να χρησιμοποιήσετε το Google Search Console και το συμπεριλαμβανόμενο εργαλείο αφαίρεσης URL:

Ένα παρόμοιο εργαλείο είναι διαθέσιμο στο Yandex Webmaster. Διαβάστε περισσότερα σχετικά με την κατάργηση σελίδων από το ευρετήριο της μηχανής αναζήτησης σε ξεχωριστό άρθρο.
Έλεγχος robots.txt
Συνεχίζοντας το θέμα με το Google, μπορείτε να χρησιμοποιήσετε ένα ακόμη Εργαλείο αναζήτησηςΚονσόλαστε και ελέγξτε το αρχείο robots.txt για να δείτε εάν έχει ρυθμιστεί σωστά ώστε να αποτρέπεται η ευρετηρίαση ορισμένων σελίδων:

Για να το κάνετε αυτό, απλώς εισαγάγετε τις διευθύνσεις URL που πρέπει να ελεγχθούν στο πεδίο κειμένου και κάντε κλικ στο κουμπί Έλεγχος - ως αποτέλεσμα του ελέγχου, θα αποκαλυφθεί εάν αυτή η σελίδα απαγορεύεται να δημιουργήσει ευρετήριο ή εάν το περιεχόμενό της είναι προσβάσιμο σε ρομπότ αναζήτησης .
Το Yandex διαθέτει επίσης ένα παρόμοιο εργαλείο που βρίσκεται στο Webmaster, ο έλεγχος πραγματοποιείται με παρόμοιο τρόπο:

Εάν δεν ξέρετε πώς να δημιουργήσετε σωστά ένα αρχείο, τότε απλώς δημιουργήστε ένα κενό έγγραφο κειμένου με το όνομα robots.txt, και καθώς μελετάτε τα χαρακτηριστικά του CMS και της δομής του ιστότοπου, συμπληρώστε το με τις απαραίτητες οδηγίες.
Για πληροφορίες σχετικά με το πώς να μεταγλωττίσετε σωστά ένα αρχείο, ακολουθήστε τον σύνδεσμο. Τα λέμε!
Γεια σε όλους! Σήμερα θα ήθελα να σας μιλήσω για αρχείο robots.txt. Ναι, έχουν γραφτεί πολλά για αυτό στο Διαδίκτυο, αλλά, για να είμαι ειλικρινής, για πολύ καιρό εγώ ο ίδιος δεν μπορούσα να καταλάβω πώς να δημιουργήσω το σωστό robots.txt. Κατέληξα να φτιάξω ένα και υπάρχει σε όλα τα blog μου. Δεν παρατηρώ κανένα πρόβλημα, το robots.txt λειτουργεί μια χαρά.
Robots.txt για WordPress
Γιατί, στην πραγματικότητα, χρειάζεστε το robots.txt; Η απάντηση είναι ακόμα η ίδια - . Δηλαδή, η μεταγλώττιση του robots.txt είναι ένα από τα μέρη βελτιστοποίηση μηχανών αναζήτησηςιστοσελίδα (παρεμπιπτόντως, πολύ σύντομα θα υπάρξει ένα μάθημα που θα είναι αφιερωμένο σε όλη την εσωτερική βελτιστοποίηση ενός ιστότοπου στο WordPress. Επομένως, μην ξεχάσετε να εγγραφείτε στο RSS για να μην χάσετε ενδιαφέροντα υλικά.).
Μία από τις λειτουργίες αυτού του αρχείου είναι απαγόρευση ευρετηρίασηςπεριττές σελίδες ιστότοπου. Ορίζει επίσης τη διεύθυνση και δηλώνει το κύριο πράγμα καθρέφτης τοποθεσίας(ιστότοπος με ή χωρίς www).
Σημείωση: για τις μηχανές αναζήτησης, ο ίδιος ιστότοπος με www και χωρίς www είναι εντελώς διαφορετικοί ιστότοποι. Όμως, συνειδητοποιώντας ότι το περιεχόμενο αυτών των τοποθεσιών είναι το ίδιο, οι μηχανές αναζήτησης τους «κολλούν» μεταξύ τους. Επομένως, είναι σημαντικό να καταχωρήσετε τον κύριο καθρέφτη του ιστότοπου στο robots.txt. Για να μάθετε ποιος είναι ο κύριος (με www ή χωρίς www), απλώς πληκτρολογήστε τη διεύθυνση του ιστότοπού σας στο πρόγραμμα περιήγησης, για παράδειγμα, με www, εάν ανακατευθυνθείτε αυτόματα στον ίδιο ιστότοπο χωρίς www, τότε ο κύριος καθρέφτης του Ο ιστότοπός σας είναι χωρίς www. Ελπίζω να το εξήγησα σωστά.
Ήταν:
Τώρα (μετά τη μετάβαση στον ιστότοπο, το www διαγράφηκαν αυτόματα και ο ιστότοπος έγινε χωρίς www):


Λοιπόν, αυτό το πολύτιμο, κατά τη γνώμη μου, σωστό robots.txt για WordPressΜπορείτε να δείτε παρακάτω.
Σωστό για WordPress
Πράκτορας χρήστη: *
Απαγόρευση: /cgi-bin
Απαγόρευση: /wp-admin
Disallow: /wp-includes
Απαγόρευση: /wp-content/cache
Απαγόρευση: /wp-content/themes
Disallow: /trackback
Απαγόρευση: */trackback
Απαγόρευση: */*/trackback
Απαγόρευση: */*/feed/*/
Απαγόρευση: */ροή
Απαγόρευση: /*?*
Απαγόρευση: /tag
Πράκτορας χρήστη: Yandex
Απαγόρευση: /cgi-bin
Απαγόρευση: /wp-admin
Disallow: /wp-includes
Απαγόρευση: /wp-content/plugins
Απαγόρευση: /wp-content/cache
Απαγόρευση: /wp-content/themes
Disallow: /trackback
Απαγόρευση: */trackback
Απαγόρευση: */*/trackback
Απαγόρευση: */*/feed/*/
Απαγόρευση: */ροή
Απαγόρευση: /*?*
Απαγόρευση: /tag
Διοργανωτής: ιστοσελίδα
Χάρτης ιστότοπου: https://site/sitemap.xml.gz
Χάρτης ιστότοπου: https://site/sitemap.xml
Όλα όσα δίνονται παραπάνω, πρέπει να τα αντιγράψετε έγγραφο κειμένουμε την επέκταση .txt, δηλαδή, ώστε το όνομα του αρχείου να είναι robots.txt. Μπορείτε να δημιουργήσετε αυτό το έγγραφο κειμένου, για παράδειγμα, χρησιμοποιώντας το πρόγραμμα. Απλά μην ξεχνάς, σε παρακαλώ αλλάξτε τις τρεις τελευταίες γραμμέςδιεύθυνση στη διεύθυνση του ιστότοπού σας. Το αρχείο robots.txt θα πρέπει να βρίσκεται στη ρίζα του ιστολογίου, δηλαδή στον ίδιο φάκελο όπου βρίσκονται οι φάκελοι wp-content, wp-admin κ.λπ.
Για όσους είναι πολύ τεμπέληδες για να δημιουργήσουν αυτό το αρχείο κειμένου, μπορείτε απλώς να διορθώσετε 3 γραμμές και εκεί.
Θα ήθελα να σημειώσω ότι δεν χρειάζεται να επιβαρύνεστε υπερβολικά με τα τεχνικά μέρη που θα συζητηθούν παρακάτω. Τους φέρνω για «γνώση», ας πούμε, μια γενική άποψη, για να ξέρουν τι χρειάζεται και γιατί.
Η γραμμή λοιπόν:
Χρήστης-πράκτορας
ορίζει κανόνες για ορισμένες μηχανές αναζήτησης: για παράδειγμα, το "*" (αστερίσκος) υποδεικνύει ότι οι κανόνες είναι για όλες τις μηχανές αναζήτησης και ό,τι φαίνεται παρακάτω
Πράκτορας χρήστη: Yandex
σημαίνει ότι αυτοί οι κανόνες είναι μόνο για το Yandex.
Απαγορεύω
Εδώ "πετάς" ενότητες που ΔΕΝ χρειάζεται να ευρετηριαστούν από τις μηχανές αναζήτησης. Για παράδειγμα, σε μια σελίδα έχω ένα αντίγραφο άρθρων (επανάληψη) με κανονικά άρθρα και η αντιγραφή σελίδων επηρεάζει αρνητικά προώθηση μηχανών αναζήτησης, επομένως, είναι πολύ επιθυμητό αυτοί οι τομείς να πρέπει να κλείσουν από την ευρετηρίαση, κάτι που κάνουμε χρησιμοποιώντας αυτόν τον κανόνα:
Απαγόρευση: /tag
Έτσι, στο robots.txt που δίνεται παραπάνω, σχεδόν όλες οι περιττές ενότητες ενός ιστότοπου WordPress είναι κλειστές από την ευρετηρίαση, δηλαδή, απλώς αφήστε τα πάντα ως έχουν.
Πλήθος
Εδώ ορίσαμε τον κεντρικό καθρέφτη του ιστότοπου, για τον οποίο μίλησα ακριβώς παραπάνω.
Χάρτης ιστότοπου
Στις δύο τελευταίες γραμμές καθορίζουμε τη διεύθυνση έως και δύο χαρτών ιστότοπου που δημιουργήθηκαν με τη χρήση .
Πιθανά προβλήματα
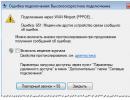
Μεταβείτε στην ενότητα Ρυθμίσεις ευρετηρίου –> Ανάλυση Robots.txt:

Ήδη εκεί, κάντε κλικ στο κουμπί «Φόρτωση robots.txt από τον ιστότοπο» και, στη συνέχεια, κάντε κλικ στο κουμπί «Έλεγχος»:

Αν δείτε κάτι σαν το ακόλουθο μήνυμα, σημαίνει ότι έχετε το σωστό robots.txt για το Yandex:

Μπορείτε επίσης να προσθέσετε τη διεύθυνση οποιουδήποτε άρθρου στον ιστότοπο στη "Λίστα διευθύνσεων URL" για να ελέγξετε εάν το robots.txt απαγορεύει την ευρετηρίαση αυτής της σελίδας:


Όπως μπορείτε να δείτε, δεν βλέπουμε καμία απαγόρευση δημιουργίας ευρετηρίου σελίδων από το robots.txt, πράγμα που σημαίνει ότι όλα είναι εντάξει :).
Ελπίζω να υπάρχουν περισσότερες ερωτήσεις, όπως: πώς να δημιουργήσετε το robots.txt ή πώς να το διορθώσετε αυτό το αρχείοΔεν θα σου συμβεί. Σε αυτό το μάθημα προσπάθησα να σας δείξω το σωστό παράδειγμα robots.txt:

Τα λέμε σύντομα!
ΥΣΤΕΡΟΓΡΑΦΟ. Πολύ πρόσφατα, τι ενδιαφέρον συνέβη; 🙂
Η αυτόματη δημιουργία robots.txt είναι κατάλληλη μόνο για τη δημιουργία βασικών αρχείων. Για τη λεπτομέρεια, πρέπει να αναλύσετε τη δομή του ιστότοπου και των καταλόγων, τα οποία πρέπει να είναι κρυφά από τις μηχανές αναζήτησης, προκειμένου να αποφευχθούν διπλότυπα στο ευρετήριο και να αποτραπεί η είσοδος περιττών πληροφοριών στη βάση δεδομένων αναζήτησης.
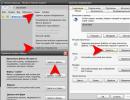
Online generator Robots.txt - συμπληρώστε τα πεδία διαδοχικά:
Ανοιξε επεξεργαστής κειμένου, επικολλήστε το αποτέλεσμα σε αυτό και αποθηκεύστε το αρχείο κάτω από το όνομα robots.txt
Μετά από αυτό, τοποθετήστε το αρχείο στον ριζικό κατάλογο του ιστότοπού σας. Το αρχείο θα πρέπει να είναι διαθέσιμο στη διεύθυνση http://your-site.com/robots.txt
Επεξηγήσεις χαρακτηριστικών για το αρχείο Robots.txt
Οδηγία "User-agent".- υποδεικνύει σε ποιο bot μηχανής αναζήτησης ισχύουν οι ακόλουθες οδηγίες. Το αρχείο Robots.txt μπορεί να δημιουργηθεί με οδηγίες που είναι ομοιόμορφες για όλα τα ρομπότ αναζήτησης ή με ξεχωριστές οδηγίες για κάθε bot.
Οδηγία «Απαγόρευση».- αυτή η οδηγία καθορίζει ποιοι κατάλογοι και αρχεία απαγορεύεται να ευρετηριαστούν από τις μηχανές αναζήτησης. Εάν δημιουργήσετε ξεχωριστές οδηγίες για κάθε bot αναζήτησης, τότε δημιουργούνται ξεχωριστοί κανόνες "Απαγόρευση" για κάθε τέτοια οδηγία. Αυτή η οδηγία μπορεί να αποτρέψει την πλήρη ευρετηρίαση του ιστότοπου (Disallow: /) ή να απαγορεύσει την ευρετηρίαση ξεχωριστούς καταλόγους. Εάν η ευρετηρίαση μεμονωμένων καταλόγων απαγορεύεται, ο αριθμός των οδηγιών «Απαγόρευση» μπορεί να είναι απεριόριστος.
Οδηγία «οικοδεσπότης».ορίζει τον κύριο καθρέφτη του ιστότοπου. Ο ιστότοπος είναι προσβάσιμος σε 2 διευθύνσεις: "με WWW" και "χωρίς WWW". Εάν το αρχείο Robots.txt δεν βρίσκεται στον διακομιστή ή δεν έχει συμπληρωθεί η καταχώριση "Host", τα ρομπότ της μηχανής αναζήτησης καθορίζουν τον κύριο καθρέφτη για τον ιστότοπο κατά την κρίση τους, αλλά εάν θέλετε να το κάνετε μόνοι σας, θα πρέπει να καθορίσετε αυτόν τον κανόνα στην οδηγία «Host».
Οδηγία "Χάρτης ιστότοπου".υποδεικνύει τη διαδρομή όπου βρίσκεται το αρχείο Sitemap.xml. Αυτό το αρχείο διευκολύνει και επιταχύνει σημαντικά την ευρετηρίαση του ιστότοπου από ρομπότ μηχανών αναζήτησης. Το αρχείο Sitemap.xml είναι ιδιαίτερα σημαντικό για ιστότοπους με μεγάλο αριθμό σελίδων και πολύπλοκη δομή ( υψηλό επίπεδοφωλιάζει).
Συμβουλές SEO:Το αρχείο Robots.txt είναι πολύ σημαντικό κατά την προώθηση ενός ιστότοπου, επειδή... υποδεικνύει στις μηχανές αναζήτησης τις επιθυμίες σας για ευρετηρίαση/απαγόρευση ευρετηρίασης ενοτήτων του ιστότοπού σας. Οι μηχανές αναζήτησης δεν εγγυώνται τη συμμόρφωση με τις απαιτήσεις στο robots.txt, αλλά τις λαμβάνουν υπόψη κατά την ευρετηρίαση. Για ιστότοπους που δημιουργούνται σε δημοφιλές CMS, υπάρχουν συνήθως έτοιμες εκδόσεις αρχείων robots.txt, αλλά εάν έχετε κάνει βελτιώσεις στη λειτουργικότητα, ίσως χρειαστεί να την προσαρμόσετε με μη αυτόματο τρόπο.
Αρχικά, θα σας πω τι είναι το robots.txt.
Robots.txt– ένα αρχείο που βρίσκεται στον ριζικό φάκελο του ιστότοπου, όπου αναγράφονται ειδικές οδηγίες για ρομπότ αναζήτησης. Αυτές οι οδηγίες είναι απαραίτητες ώστε το ρομπότ κατά την είσοδο στον ιστότοπο να μην λαμβάνει υπόψη τη σελίδα/ενότητα, δηλαδή να κλείνουμε τη σελίδα από την ευρετηρίαση.
Γιατί χρειαζόμαστε το robots.txt;
Το αρχείο robots.txt θεωρείται βασική προϋπόθεση για τη βελτιστοποίηση SEO οποιασδήποτε ιστοσελίδας. Η απουσία αυτού του αρχείου μπορεί να επηρεάσει αρνητικά τη φόρτωση από τα ρομπότ και την αργή ευρετηρίαση και, επιπλέον, ο ιστότοπος δεν θα ευρετηριαστεί πλήρως. Κατά συνέπεια, οι χρήστες δεν θα μπορούν να έχουν πρόσβαση σε σελίδες μέσω του Yandex και της Google.
Αντίκτυπος του robots.txt στις μηχανές αναζήτησης;
Μηχανές αναζήτησης(ειδικά η Google) θα ευρετηριάσει τον ιστότοπο, αλλά αν δεν υπάρχει αρχείο robots.txt, τότε, όπως είπα, όχι όλες οι σελίδες. Εάν υπάρχει τέτοιο αρχείο, τότε τα ρομπότ καθοδηγούνται από τους κανόνες που καθορίζονται σε αυτό το αρχείο. Επιπλέον, υπάρχουν διάφοροι τύποι ρομπότ αναζήτησης, ορισμένοι μπορούν να λάβουν υπόψη τον κανόνα, ενώ άλλοι τον αγνοούν. Συγκεκριμένα, το ρομπότ GoogleBot δεν λαμβάνει υπόψη τις οδηγίες Host και Crawl-Delay, το ρομπότ YandexNews σταμάτησε πρόσφατα να λαμβάνει υπόψη την οδηγία Crawl-Delay και τα ρομπότ YandexDirect και YandexVideoParser αγνοούν τις γενικά αποδεκτές οδηγίες στο robots.txt (αλλά λάβετε υπόψη αυτά που είναι γραμμένα ειδικά για αυτούς).
Ο ιστότοπος φορτώνεται περισσότερο από ρομπότ που φορτώνουν περιεχόμενο από τον ιστότοπό σας. Αντίστοιχα, αν πούμε στο ρομπότ ποιες σελίδες να ευρετηριάσει και ποιες να αγνοήσει, καθώς και σε ποια χρονικά διαστήματα να φορτώνει περιεχόμενο από τις σελίδες (αυτό ισχύει περισσότερο για μεγάλους ιστότοπους που έχουν περισσότερες από 100.000 σελίδες στο ευρετήριο της μηχανής αναζήτησης). Αυτό θα διευκολύνει πολύ το ρομπότ να δημιουργήσει ευρετήριο και να κατεβάσει περιεχόμενο από τον ιστότοπο.
Τα αρχεία που δεν είναι απαραίτητα για τις μηχανές αναζήτησης περιλαμβάνουν αρχεία που ανήκουν στο CMS, για παράδειγμα, στο Wordpress – /wp-admin/. Επιπλέον, σενάρια ajax, json υπεύθυνα για αναδυόμενες φόρμες, banner, έξοδο captcha και ούτω καθεξής.
Για τα περισσότερα ρομπότ, συνιστώ επίσης τον αποκλεισμό όλων των αρχείων Javascript και CSS από την ευρετηρίαση. Αλλά για το GoogleBot και το Yandex, είναι καλύτερο να καταχωρίσετε τέτοια αρχεία, καθώς χρησιμοποιούνται από τις μηχανές αναζήτησης για να αναλύσουν την ευκολία του ιστότοπου και την κατάταξή του.
Τι είναι μια οδηγία robots.txt;

Οδηγίες– αυτοί είναι οι κανόνες για τα ρομπότ αναζήτησης. Τα πρώτα πρότυπα για τη γραφή robots.txt και, κατά συνέπεια, εμφανίστηκαν το 1994 και το εκτεταμένο πρότυπο το 1996. Ωστόσο, όπως ήδη γνωρίζετε, δεν υποστηρίζουν όλα τα ρομπότ ορισμένες οδηγίες. Επομένως, παρακάτω έχω περιγράψει από τι καθοδηγούνται τα κύρια ρομπότ κατά την ευρετηρίαση σελίδων ιστότοπου.
Τι σημαίνει User-agent;
Αυτή είναι η πιο σημαντική οδηγία που καθορίζει ποια ρομπότ αναζήτησης θα ακολουθήσουν περαιτέρω κανόνες.
Για όλα τα ρομπότ:
Για ένα συγκεκριμένο bot:
Χρήστης-πράκτορας: Googlebot
Η εγγραφή στο robots.txt δεν είναι σημαντική, μπορείτε να γράψετε και Googlebot και googlebot
Ρομπότ αναζήτησης Google
Ρομπότ αναζήτησης Yandex
|
Το κύριο ρομπότ ευρετηρίου της Yandex |
|
|
Χρησιμοποιείται στην υπηρεσία Yandex.Images |
|
|
Χρησιμοποιείται στην υπηρεσία Yandex.Video |
|
|
Δεδομένα πολυμέσων |
|
|
Αναζήτηση ιστολογίου |
|
|
Ένα ρομπότ αναζήτησης που έχει πρόσβαση σε μια σελίδα όταν την προσθέτει μέσω της φόρμας "Προσθήκη URL". |
|
|
ρομπότ που ευρετηριάζει εικονίδια ιστότοπου (favicons) |
|
|
Yandex.Direct |
|
|
Yandex.Metrica |
|
|
Χρησιμοποιείται στην υπηρεσία Yandex.Catalog |
|
|
Χρησιμοποιείται στην υπηρεσία Yandex.News |
|
|
YandexImageResizer |
Ρομπότ αναζήτησης υπηρεσιών κινητής τηλεφωνίας |
Αναζήτηση ρομπότ Bing, Yahoo, Mail.ru, Rambler
Απαγόρευση και Αποδοχή οδηγιών
Να μην επιτρέπεται η δημιουργία ευρετηρίασης μπλοκ ενοτήτων και σελίδων του ιστότοπού σας. Αντίστοιχα, το Allow, αντίθετα, τα ανοίγει.
Υπάρχουν κάποιες ιδιαιτερότητες.
Πρώτον, οι πρόσθετοι τελεστές είναι οι *, $ και #. Σε τι χρησιμεύουν;
“*” – αυτός είναι οποιοσδήποτε αριθμός χαρακτήρων και η απουσία τους. Από προεπιλογή, βρίσκεται ήδη στο τέλος της γραμμής, οπότε δεν έχει νόημα να το ξαναβάλουμε.
“$” – υποδεικνύει ότι ο χαρακτήρας πριν από αυτό πρέπει να είναι τελευταίος.
“#” – σχόλιο, το ρομπότ δεν λαμβάνει υπόψη όλα όσα έρχονται μετά από αυτό το σύμβολο.
Παραδείγματα χρήσης Disallow:
Απαγόρευση: *?s=
Απαγόρευση: /κατηγορία/
Αντίστοιχα, το ρομπότ αναζήτησης θα κλείσει σελίδες όπως:
Ωστόσο, σελίδες όπως αυτή θα είναι ανοιχτές για ευρετηρίαση:
Τώρα πρέπει να καταλάβετε πώς εκτελούνται οι κανόνες ένθεσης. Η σειρά με την οποία συντάσσονται οι οδηγίες είναι απολύτως σημαντική. Η κληρονομικότητα κανόνων καθορίζεται από το ποιοι κατάλογοι καθορίζονται, δηλαδή εάν θέλουμε να αποκλείσουμε μια σελίδα/έγγραφο από την ευρετηρίαση, αρκεί να γράψουμε μια οδηγία. Ας δούμε ένα παράδειγμα
Αυτό είναι το αρχείο μας robots.txt
Απαγόρευση: /template/
Αυτή η οδηγία μπορεί επίσης να καθοριστεί οπουδήποτε και πολλά αρχεία χάρτη ιστότοπου μπορούν να καθοριστούν.
Οδηγία κεντρικού υπολογιστή στο robots.txt
Αυτή η οδηγία είναι απαραίτητη για την ένδειξη του κύριου καθρέφτη του ιστότοπου (συχνά με ή χωρίς www). Λάβετε υπόψη ότι η οδηγία κεντρικού υπολογιστή καθορίζεται χωρίς το πρωτόκολλο http://, αλλά με το πρωτόκολλο https://. Η οδηγία λαμβάνεται υπόψη μόνο από τα ρομπότ αναζήτησης Yandex και Mail.ru και άλλα ρομπότ, συμπεριλαμβανομένου του GoogleBot, δεν θα λάβουν υπόψη τον κανόνα. Ο κεντρικός υπολογιστής πρέπει να καθοριστεί μία φορά στο αρχείο robots.txt
Παράδειγμα με http://
Διοργανωτής: website.ru
Παράδειγμα με https://
Οδηγία καθυστέρησης ανίχνευσης
Ορίζει το χρονικό διάστημα για την ευρετηρίαση σελίδων ιστότοπου από ένα ρομπότ αναζήτησης. Η τιμή υποδεικνύεται σε δευτερόλεπτα και χιλιοστά του δευτερολέπτου.
Παράδειγμα:
Χρησιμοποιείται κυρίως σε μεγάλα ηλεκτρονικά καταστήματα, ιστότοπους πληροφοριών, πύλες, όπου η επισκεψιμότητα του ιστότοπου είναι από 5.000 ανά ημέρα. Είναι απαραίτητο για το ρομπότ αναζήτησης να υποβάλει αίτημα ευρετηρίασης μέσα σε ένα ορισμένο χρονικό διάστημα. Εάν αυτή η οδηγία δεν προσδιορίζεται, μπορεί να δημιουργήσει σοβαρό φόρτο στον διακομιστή.
Η βέλτιστη τιμή καθυστέρησης ανίχνευσης είναι διαφορετική για κάθε ιστότοπο. Για τις μηχανές αναζήτησης Mail, Bing, Yahoo, η τιμή μπορεί να οριστεί σε μια ελάχιστη τιμή 0,25, 0,3, καθώς αυτά τα ρομπότ μηχανών αναζήτησης μπορούν να ανιχνεύουν τον ιστότοπό σας μία φορά το μήνα, 2 μήνες κ.λπ. (πολύ σπάνια). Για το Yandex, είναι καλύτερο να ορίσετε υψηλότερη τιμή.
Εάν ο φόρτος στον ιστότοπό σας είναι ελάχιστος, τότε δεν έχει νόημα να προσδιορίσετε αυτήν την οδηγία.
Οδηγία Clean-param
Ο κανόνας είναι ενδιαφέρον γιατί λέει στον ανιχνευτή ότι οι σελίδες με συγκεκριμένες παραμέτρους δεν χρειάζεται να ευρετηριαστούν. Προβλέπονται 2 επιχειρήματα: Διεύθυνση Ιστοσελίδαςκαι παράμετρος. Αυτή η οδηγία υποστηρίζεται μηχανή αναζήτησης Yandex.
Παράδειγμα:
Απαγόρευση: /admin/
Απαγόρευση: /plugins/
Απαγόρευση: /search/
Απαγόρευση: /cart/
Απαγόρευση: *ταξινόμηση=
Απαγόρευση: *προβολή=
Πράκτορας χρήστη: GoogleBot
Απαγόρευση: /admin/
Απαγόρευση: /plugins/
Απαγόρευση: /search/
Απαγόρευση: /cart/
Απαγόρευση: *ταξινόμηση=
Απαγόρευση: *προβολή=
Να επιτρέπεται: /plugins/*.css
Να επιτρέπεται: /plugins/*.js
Να επιτρέπεται: /plugins/*.png
Να επιτρέπεται: /plugins/*.jpg
Να επιτρέπεται: /plugins/*.gif
Πράκτορας χρήστη: Yandex
Απαγόρευση: /admin/
Απαγόρευση: /plugins/
Απαγόρευση: /search/
Απαγόρευση: /cart/
Απαγόρευση: *ταξινόμηση=
Απαγόρευση: *προβολή=
Να επιτρέπεται: /plugins/*.css
Να επιτρέπεται: /plugins/*.js
Να επιτρέπεται: /plugins/*.png
Να επιτρέπεται: /plugins/*.jpg
Να επιτρέπεται: /plugins/*.gif
Clean-Param: utm_source&utm_medium&utm_campaign
Στο παράδειγμα, καταγράψαμε τους κανόνες για 3 διαφορετικά bots.
Πού να προσθέσω το robots.txt;
Προστέθηκε στον ριζικό φάκελο του ιστότοπου. Επιπλέον, για να μπορείτε να ακολουθήσετε τον σύνδεσμο:
Πώς να ελέγξετε το robots.txt;
Yandex Webmaster
Στην καρτέλα Εργαλεία, επιλέξτε Ανάλυση Robots.txt και, στη συνέχεια, κάντε κλικ στον έλεγχο
Google Search Console
Στην καρτέλα Ερευναεπιλέγω Εργαλείο επιθεώρησης αρχείων Robots.txtκαι μετά κάντε κλικ στον έλεγχο.
Συμπέρασμα:
Το αρχείο robots.txt πρέπει να υπάρχει σε κάθε ιστότοπο που προωθείται και μόνο η σωστή διαμόρφωσή του θα σας επιτρέψει να αποκτήσετε την απαραίτητη ευρετηρίαση.
Και τέλος, αν έχετε οποιεσδήποτε ερωτήσεις, ρωτήστε τις στα σχόλια κάτω από το άρθρο και επίσης αναρωτιέμαι, πώς γράφετε το robots.txt;
Αυτό το άρθρο περιέχει ένα παράδειγμα του βέλτιστου, κατά τη γνώμη μου, κώδικα για το αρχείο robots.txt για WordPress, τον οποίο μπορείτε να χρησιμοποιήσετε στους ιστότοπούς σας.
Για αρχή, ας θυμηθούμε γιατί χρειάζεστε το robots.txt- το αρχείο robots.txt χρειάζεται αποκλειστικά για τα ρομπότ αναζήτησης να τους «λένε» ποιες ενότητες/σελίδες του ιστότοπου να επισκεφτούν και ποιες δεν πρέπει να επισκεφτούν. Οι σελίδες που έχουν κλείσει από επίσκεψη δεν θα περιλαμβάνονται στο ευρετήριο της μηχανής αναζήτησης (Yandex, Google, κ.λπ.).
Επιλογή 1: Βέλτιστος κώδικας robots.txt για WordPress
User-agent: * Disallow: /cgi-bin # classic... Disallow: /? # όλες οι παράμετροι ερωτήματος στην κύρια σελίδα Απαγόρευση: /wp- # όλα τα αρχεία WP: /wp-json/, /wp-includes, /wp-content/plugins Απαγόρευση: *?s= # αναζήτηση Απαγόρευση: *&s= # αναζήτηση Disallow: /search # search Απαγόρευση: /author/ # αρχείο συγγραφέα Απαγόρευση: *?attachment_id= # σελίδα συνημμένου. Στην πραγματικότητα, υπάρχει μια ανακατεύθυνση σε αυτό... Απαγόρευση: */embed # all embeddings Disallow: */page/ # όλοι οι τύποι σελιδοποίησης Επιτρέπονται: */uploads # open uploads Allow: /*/*.js # inside /wp - (/ */ - για προτεραιότητα) Να επιτρέπεται: /*/*.css # inside /wp- (/*/ - για προτεραιότητα) Να επιτρέπεται: /wp-*.png # εικόνες σε πρόσθετα, φάκελο προσωρινής μνήμης κ.λπ. Να επιτρέπονται: /wp-*.jpg # εικόνες σε προσθήκες, φάκελο προσωρινής μνήμης κ.λπ. Να επιτρέπονται: /wp-*.jpeg # εικόνες σε προσθήκες, φάκελο προσωρινής μνήμης κ.λπ. Να επιτρέπονται: /wp-*.gif # εικόνες σε πρόσθετα, φάκελο προσωρινής μνήμης κ.λπ. Να επιτρέπονται: /wp-*.svg # εικόνες σε προσθήκες, φάκελο προσωρινής μνήμης κ.λπ. Να επιτρέπονται: /wp-*.pdf # αρχεία σε προσθήκες, φάκελο προσωρινής μνήμης κ.λπ. #Disallow: /wp/ # όταν το WP είναι εγκατεστημένο στον υποκατάλογο wp Χάρτης ιστότοπου: http://example.com/sitemap.xml Χάρτης ιστότοπου: http://example.com/sitemap2.xml # άλλο αρχείο #Χάρτης ιστότοπου: http:/ / example.com/sitemap.xml.gz # συμπιεσμένη έκδοση (.gz) # Έκδοση κώδικα: 1.1 # Μην ξεχάσετε να αλλάξετε το «site.ru» στον ιστότοπό σας.Ανάλυση κώδικα:
- Disallow: /cgi-bin - κλείνει τον κατάλογο σεναρίων στο διακομιστή
- Disallow: /feed - κλείνει τη ροή RSS του ιστολογίου
- Disallow: /trackback - κλείνει τις ειδοποιήσεις
- Disallow: ?s= ή Disallow: *?s= - κλείνει τις σελίδες αναζήτησης
- Disallow: */page/ - κλείνει όλους τους τύπους σελιδοποίησης
Ο κανόνας του χάρτη ιστότοπου: http://example.com/sitemap.xml οδηγεί το ρομπότ σε ένα αρχείο με χάρτη ιστότοπου σε μορφή XML. Εάν έχετε ένα τέτοιο αρχείο στον ιστότοπό σας, τότε γράψτε την πλήρη διαδρομή προς αυτό. Μπορεί να υπάρχουν πολλά τέτοια αρχεία, τότε υποδεικνύουμε τη διαδρομή προς το καθένα ξεχωριστά.
Στη γραμμή Host: site.ru υποδεικνύουμε τον κύριο καθρέφτη του ιστότοπου. Εάν ένας ιστότοπος έχει καθρέφτες (αντίγραφα του ιστότοπου σε άλλους τομείς), τότε για να τα ευρετηριάσει όλα εξίσου το Yandex, πρέπει να καθορίσετε τον κύριο καθρέφτη. Οδηγία κεντρικού υπολογιστή: μόνο το Yandex καταλαβαίνει, η Google δεν καταλαβαίνει! Εάν ο ιστότοπος λειτουργεί σύμφωνα με το πρωτόκολλο https, τότε πρέπει να καθοριστεί στο Host: Host: http://example.com
Από την τεκμηρίωση του Yandex: "Ο κεντρικός υπολογιστής είναι μια ανεξάρτητη οδηγία και λειτουργεί οπουδήποτε στο αρχείο (διατομή)." Επομένως, το βάζουμε στην κορυφή ή στο τέλος του αρχείου, μέσα από μια κενή γραμμή.
Στη γραμμή User-agent: * υποδεικνύουμε ότι όλοι οι παρακάτω κανόνες θα λειτουργούν για όλα τα ρομπότ αναζήτησης *. Εάν χρειάζεστε αυτούς τους κανόνες για να λειτουργούν μόνο για ένα συγκεκριμένο ρομπότ, τότε αντί για * υποδεικνύουμε το όνομα του ρομπότ (User-agent: Yandex, User-agent: Googlebot).
Στη γραμμή Allow: */uploads, επιτρέπουμε σκόπιμα την ευρετηρίαση σελίδων που περιέχουν /uploads. Αυτός ο κανόνας είναι υποχρεωτικός, γιατί παραπάνω, απαγορεύουμε την ευρετηρίαση σελίδων που ξεκινούν με /wp- και /wp-συμπεριλαμβανεται σε /wp-content/uploads. Επομένως, για να παρακάμψετε τον κανόνα Disallow: /wp-, χρειάζεστε τη γραμμή Allow: */uploads , γιατί για συνδέσμους όπως /wp-content/uploads/...Ενδέχεται να έχουμε εικόνες που πρέπει να ευρετηριαστούν και μπορεί επίσης να υπάρχουν κάποια ληφθέντα αρχεία που δεν χρειάζεται να κρύψουμε. Να επιτρέπεται: μπορεί να είναι "πριν" ή "μετά" Απαγόρευση: .
Οι υπόλοιπες γραμμές απαγορεύουν στα ρομπότ να «ακολουθούν» συνδέσμους που ξεκινούν με:
Επειδή απαιτείται η παρουσία ανοιχτών ροών, για παράδειγμα, για το Yandex Zen, όταν πρέπει να συνδέσετε έναν ιστότοπο σε ένα κανάλι (χάρη στον σχολιαστή "Digital"). Ίσως χρειάζονται ανοιχτές τροφοδοσίες αλλού.
Ταυτόχρονα, οι ροές έχουν τη δική τους μορφή στις κεφαλίδες απόκρισης, χάρη στις οποίες οι μηχανές αναζήτησης κατανοούν ότι αυτή δεν είναι μια σελίδα HTML, αλλά μια τροφοδοσία και, προφανώς, την επεξεργάζονται κάπως διαφορετικά.
Η οδηγία Host δεν χρειάζεται πλέον για το Yandex
Η Yandex εγκαταλείπει εντελώς την οδηγία Host και την έχει αντικαταστήσει με μια ανακατεύθυνση 301. Ο κεντρικός υπολογιστής μπορεί να αφαιρεθεί με ασφάλεια από το robots.txt. Ωστόσο, είναι σημαντικό όλοι οι καθρέφτες ιστότοπου να έχουν ανακατεύθυνση 301 στον κύριο ιστότοπο (κύριος καθρέφτης).
Αυτό είναι σημαντικό: κανόνες ταξινόμησης πριν από την επεξεργασία
Η Yandex και η Google επεξεργάζονται τις οδηγίες Αποδοχή και Απαγόρευση όχι με τη σειρά με την οποία καθορίζονται, αλλά πρώτα τις ταξινομούν από σύντομο κανόνα σε μεγάλο και στη συνέχεια επεξεργάζονται τον τελευταίο κανόνα αντιστοίχισης:
User-agent: * Allow: */uploads Disallow: /wp-
θα διαβαστεί ως εξής:
User-agent: * Disallow: /wp- Allow: */uploads
Για να κατανοήσετε γρήγορα και να εφαρμόσετε τη δυνατότητα ταξινόμησης, θυμηθείτε αυτόν τον κανόνα: «όσο μεγαλύτερος είναι ο κανόνας στο robots.txt, τόσο μεγαλύτερη προτεραιότητα έχει. Εάν το μήκος των κανόνων είναι το ίδιο, τότε δίνεται προτεραιότητα στην οδηγία Allow».
Επιλογή 2: Τυπικό robots.txt για WordPress
Δεν ξέρω γιατί, αλλά είμαι υπέρ της πρώτης επιλογής! Επειδή είναι πιο λογικό - δεν χρειάζεται να αντιγράψετε εντελώς την ενότητα για να υποδείξετε την οδηγία Host για το Yandex, η οποία είναι διατομεακή (καταλαβαίνεται από το ρομπότ οπουδήποτε στο πρότυπο, χωρίς να υποδεικνύει σε ποιο ρομπότ αναφέρεται). Όσον αφορά την μη τυπική οδηγία Allow, λειτουργεί για Yandex και Google και εάν δεν ανοίξει το φάκελο μεταφορτώσεων για άλλα ρομπότ που δεν την καταλαβαίνουν, τότε στο 99% των περιπτώσεων αυτό δεν συνεπάγεται τίποτα επικίνδυνο. Δεν έχω παρατηρήσει ακόμη ότι τα πρώτα ρομπότ δεν λειτουργούν όπως θα έπρεπε.
Ο παραπάνω κωδικός είναι λίγο λανθασμένος. Ευχαριστώ τον σχολιαστή " " για την επισήμανση της ανακρίβειας, αν και έπρεπε να καταλάβω τι ήταν ο ίδιος. Και αυτό είναι που κατέληξα (μπορεί να κάνω λάθος):
- Η οδηγία Yandex Host: πρέπει να χρησιμοποιείται μετά το Disallow:, επειδή ορισμένα ρομπότ (όχι το Yandex και η Google) ενδέχεται να μην την κατανοούν και γενικά να απορρίπτουν το robots.txt. Η ίδια η Yandex, κρίνοντας από την τεκμηρίωση, δεν ενδιαφέρεται καθόλου πού και πώς να χρησιμοποιήσετε το Host:, ακόμα κι αν γενικά δημιουργείτε το robots.txt με μία μόνο γραμμή Host: www.site.ru για να κολλήσετε όλους τους καθρέφτες του ιστότοπου μαζί.
Ορισμένα ρομπότ (όχι το Yandex και η Google) δεν κατανοούν περισσότερες από 2 οδηγίες: User-agent: και Disallow:
3. Χάρτης ιστότοπου: μια διατομεακή οδηγία για το Yandex και την Google και προφανώς και για πολλά άλλα ρομπότ, οπότε το γράφουμε στο τέλος με μια κενή γραμμή και θα λειτουργήσει για όλα τα ρομπότ ταυτόχρονα.
Με βάση αυτές τις τροπολογίες, ο σωστός κωδικός θα πρέπει να μοιάζει με αυτό:
Πράκτορας χρήστη: Yandex Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-json/ Disallow: /wp-login.php Disallow: /wp-register.php Disallow: */embed Disallow: */page/ Disallow: /cgi-bin Disallow: *?s= Allow: /wp-admin/admin-ajax.php Host: site.ru User-agent: * Disallow: /wp-admin Disallow : /wp-includes Disallow: /wp-content/plugins Disallow: /wp-json/ Disallow: /wp-login.php Disallow: /wp-register.php Disallow: */embed Disallow: */page/ Disallow: / cgi-bin Disallow: *?s= Allow: /wp-admin/admin-ajax.php Χάρτης ιστότοπου: http://example.com/sitemap.xmlΑς το προσθέσουμε μόνοι μας
Εάν πρέπει να αποκλείσετε άλλες σελίδες ή ομάδες σελίδων, μπορείτε να προσθέσετε έναν κανόνα (οδηγία) παρακάτω Απαγορεύω:. Για παράδειγμα, πρέπει να κλείσουμε όλες τις καταχωρήσεις σε μια κατηγορία από την ευρετηρίαση Νέα, τότε πριν Χάρτης ιστότοπου:προσθέστε έναν κανόνα:
Απαγόρευση: /ειδήσεις
Εμποδίζει τα ρομπότ να ακολουθούν τέτοιους συνδέσμους:
- http://example.com/news
- http://example.com/news/drugoe-nazvanie/
Εάν πρέπει να κλείσετε τυχόν εμφανίσεις του /news , τότε γράψτε:
Απαγόρευση: */ειδήσεις
- http://example.com/news
- http://example.com/my/news/drugoe-nazvanie/
- http://example.com/category/newsletter-nazvanie.html
Μπορείτε να μελετήσετε τις οδηγίες του robots.txt με περισσότερες λεπτομέρειες στη σελίδα βοήθειας του Yandex (αλλά να έχετε κατά νου ότι δεν λειτουργούν όλοι οι κανόνες που περιγράφονται εκεί για την Google).
Έλεγχος και τεκμηρίωση του Robots.txt
Μπορείτε να ελέγξετε εάν οι προβλεπόμενοι κανόνες λειτουργούν σωστά χρησιμοποιώντας τους ακόλουθους συνδέσμους:
- Yandex: http://webmaster.yandex.ru/robots.xml.
- Στο Google αυτό γίνεται στο Κονσόλα αναζήτησης. Χρειάζεστε εξουσιοδότηση και την παρουσία του ιστότοπου στον πίνακα webmaster...
- Υπηρεσία για τη δημιουργία αρχείου robots.txt: http://pr-cy.ru/robots/
- Υπηρεσία για τη δημιουργία και τον έλεγχο robots.txt: https://seolib.ru/tools/generate/robots/
Καθυστέρηση ανίχνευσης - timeout για τρελά ρομπότ (δεν λαμβάνεται υπόψη από το 2018)
Yandex
Έχοντας αναλύσει επιστολές τα τελευταία δύο χρόνια προς την υποστήριξή μας σχετικά με ζητήματα ευρετηρίασης, ανακαλύψαμε ότι ένας από τους κύριους λόγους για την αργή λήψη των εγγράφων είναι μια εσφαλμένα ρυθμισμένη οδηγία καθυστέρησης ανίχνευσης στο robots.txt […] Έτσι ώστε οι ιδιοκτήτες ιστότοπων να μην είναι πλέον πρέπει να ανησυχείτε για αυτό και για να είναι όλα αληθινά απαιτούμενες σελίδεςοι ιστότοποι εμφανίστηκαν και ενημερώθηκαν γρήγορα στην αναζήτηση, αποφασίσαμε να αρνηθούμε να λάβουμε υπόψη την οδηγία για την καθυστέρηση ανίχνευσης.
Όταν το ρομπότ Yandex σαρώνει τον ιστότοπο σαν τρελό και αυτό δημιουργεί περιττό φορτίο στον διακομιστή. Μπορείτε να ζητήσετε από το ρομπότ να «επιβραδύνει».
Για να το κάνετε αυτό, πρέπει να χρησιμοποιήσετε την οδηγία Crawl-Delay. Υποδεικνύει το χρόνο σε δευτερόλεπτα που το ρομπότ πρέπει να παραμείνει σε αδράνεια (αναμονή) για να σαρώσει κάθε επόμενη σελίδα του ιστότοπου.
Για συμβατότητα με ρομπότ που δεν ακολουθούν καλά το τυπικό robots.txt, η καθυστέρηση ανίχνευσης πρέπει να καθοριστεί στην ομάδα (στην ενότητα User-Agent) αμέσως μετά το Disallow and Allow
Το Yandex Robot κατανοεί κλασματικές τιμές, για παράδειγμα, 0,5 (μισό δευτερόλεπτο). Αυτό δεν εγγυάται ότι το ρομπότ αναζήτησης θα επισκέπτεται τον ιστότοπό σας κάθε μισό δευτερόλεπτο, αλλά σας επιτρέπει να ανιχνεύσετε τον ιστότοπο πιο γρήγορα.
User-agent: Yandex Disallow: /wp-admin Disallow: /wp-includes Crawl-delay: 1,5 # timeout 1,5 seconds User-agent: * Disallow: /wp-admin Disallow: /wp-includes Allow: /wp-* . gif Καθυστέρηση ανίχνευσης: 2 # timeout 2 δευτερόλεπτα
Το Googlebot δεν κατανοεί την οδηγία για την καθυστέρηση ανίχνευσης. Το χρονικό όριο για τα ρομπότ του μπορεί να καθοριστεί στον πίνακα webmaster.
Ρώτησα την Yandex...
Έκανα μια ερώτηση στην τεχνολογία. Υποστήριξη Yandex σχετικά με τη διατομεακή χρήση των οδηγιών Host και Sitemap:
Ερώτηση:
Γειά σου!
Γράφω ένα άρθρο για το robots.txt στο ιστολόγιό μου. Θα ήθελα να λάβω μια απάντηση σε αυτήν την ερώτηση (δεν βρήκα ξεκάθαρο "ναι" στην τεκμηρίωση):Εάν πρέπει να κολλήσω όλους τους καθρέφτες και για αυτό χρησιμοποιώ την οδηγία Host στην αρχή του αρχείου robots.txt:
Κεντρικός υπολογιστής: site.ru Πράκτορας χρήστη: * Απαγόρευση: /asd
Θα υπάρχουν σε αυτό το παράδειγμαπρέπει το Host: site.ru να λειτουργεί σωστά; Θα δείξει στα ρομπότ ότι το site.ru είναι ο κύριος καθρέφτης; Εκείνοι. Χρησιμοποιώ αυτήν την οδηγία όχι σε μια ενότητα, αλλά ξεχωριστά (στην αρχή του αρχείου) χωρίς να υποδεικνύω σε ποιον χρήστη-πράκτορα αναφέρεται.
Ήθελα επίσης να μάθω εάν η οδηγία Χάρτη ιστότοπου πρέπει να χρησιμοποιείται μέσα σε μια ενότητα ή μπορεί να χρησιμοποιηθεί εκτός: για παράδειγμα, μέσα από μια κενή γραμμή, μετά την ενότητα;
Πράκτορας χρήστη: Yandex Disallow: /asd User-agent: * Disallow: /asd Χάρτης ιστότοπου: http://example.com/sitemap.xml
Θα κατανοήσει το ρομπότ την οδηγία για τον χάρτη ιστότοπου σε αυτό το παράδειγμα;
Ελπίζω να λάβω μια απάντηση από εσάς που θα βάλει τέλος στις αμφιβολίες μου.
Απάντηση:
Γειά σου!
Οι οδηγίες Host και Sitemap είναι διατομεακές, επομένως θα χρησιμοποιηθούν από το ρομπότ ανεξάρτητα από τη θέση στο αρχείο robots.txt όπου καθορίζονται.
--
Με εκτίμηση, Platon Shchukin
Υπηρεσία υποστήριξης Yandex
συμπέρασμα
Είναι σημαντικό να θυμάστε ότι οι αλλαγές στο robots.txt σε έναν ήδη λειτουργικό ιστότοπο θα είναι ορατές μόνο μετά από αρκετούς μήνες (2-3 μήνες).
Υπάρχουν φήμες ότι η Google μπορεί μερικές φορές να αγνοήσει τους κανόνες στο robots.txt και να εισάγει μια σελίδα στο ευρετήριο, εάν θεωρεί ότι η σελίδα είναι πολύ μοναδική και χρήσιμη και απλώς πρέπει να βρίσκεται στο ευρετήριο. Ωστόσο, άλλες φήμες διαψεύδουν αυτήν την υπόθεση από το γεγονός ότι οι άπειροι βελτιστοποιητές μπορούν να καθορίσουν εσφαλμένα τους κανόνες στο robots.txt και έτσι να κλείσουν τις απαραίτητες σελίδες από την ευρετηρίαση και να αφήσουν περιττές. Τείνω περισσότερο στη δεύτερη υπόθεση...
Στην υπηρεσία avi1.ru μπορείτε πλέον να αγοράσετε προώθηση SMM σε περισσότερες από 7 από τις πιο δημοφιλείς στα κοινωνικά δίκτυα. Ταυτόχρονα, δώστε προσοχή στο αρκετά χαμηλό κόστος όλων των υπηρεσιών του ιστότοπου.