Group by sql how it works. Grouping using group by and filtering groups with having
Last update: 07/19/2017
T-SQL uses the GROUP BY and HAVING statements to group data, using the following formal syntax:
SELECT columns FROM table
GROUP BY
The GROUP BY clause determines how the rows will be grouped.
For example, let's group products by manufacturer
SELECT Manufacturer, COUNT(*) AS ModelsCount FROM Products GROUP BY Manufacturer
The first column in the SELECT statement - Manufacturer represents the name of the group, and the second column - ModelsCount represents the result of the Count function, which calculates the number of rows in the group.
It is worth considering that any column that is used in a SELECT statement (not counting columns that store the result of aggregate functions) must be specified after the GROUP BY clause. So, for example, in the case above, the Manufacturer column is specified in both the SELECT and GROUP BY clauses.
And if the SELECT statement selects on one or more columns and also uses aggregate functions, then you must use the GROUP BY clause. Thus, the following example will not work because it does not contain a grouping expression:
SELECT Manufacturer, COUNT(*) AS ModelsCount FROM Products
Another example, let's add a grouping by the number of products:
SELECT Manufacturer, ProductCount, COUNT(*) AS ModelsCount FROM Products GROUP BY Manufacturer, ProductCount
The GROUP BY clause can group by multiple columns.
If the column you are grouping on contains a NULL value, the rows with the NULL value will form a separate group.
Note that the GROUP BY clause must come after the WHERE clause but before the ORDER BY clause:
SELECT Manufacturer, COUNT(*) AS ModelsCount FROM Products WHERE Price > 30000 GROUP BY Manufacturer ORDER BY ModelsCount DESC
Group filtering. HAVING
Operator HAVING determines which groups will be included in the output result, that is, it filters groups.
The use of HAVING is in many ways similar to the use of WHERE. Only WHERE is used to filter rows, HAVING is used to filter groups.
For example, let’s find all product groups by manufacturer for which more than 1 model is defined:
SELECT Manufacturer, COUNT(*) AS ModelsCount FROM Products GROUP BY Manufacturer HAVING COUNT(*) > 1
In this case, in one command we can use WHERE and HAVING expressions:
SELECT Manufacturer, COUNT(*) AS ModelsCount FROM Products WHERE Price * ProductCount > 80000 GROUP BY Manufacturer HAVING COUNT(*) > 1
That is, in this case, the rows are first filtered: those products are selected whose total cost is more than 80,000. Then the selected products are grouped by manufacturer. And then the groups themselves are filtered - those groups that contain more than 1 model are selected.
If it is necessary to sort, then the ORDER BY expression comes after the HAVING expression:
SELECT Manufacturer, COUNT(*) AS Models, SUM(ProductCount) AS Units FROM Products WHERE Price * ProductCount > 80000 GROUP BY Manufacturer HAVING SUM(ProductCount) > 2 ORDER BY Units DESC
In this case, the grouping is by manufacturer, and the number of models for each manufacturer (Models) and the total number of all products for all these models (Units) are also selected. At the end, the groups are sorted by number of products in descending order.
In this article, I will tell you how data is grouped, how to correctly use group by and having inside SQL queries using the example of several queries.
Most information in databases is stored in detailed form. However, there is often a need to obtain reports. For example, find out the total number of user comments or perhaps the quantity of goods in warehouses. There are a lot of similar tasks. Therefore, the SQL language specifically provides for such cases the group by and having constructs, which allow, respectively, to group and filter the resulting groups of data.
However, their use causes many problems for novice authors of software creations. They do not quite correctly interpret the results obtained and the data grouping mechanism itself. Therefore, let's figure out in practice what happens and how.
As part of the example, I will consider just one table. The reason is simple, these operators are already applied to the resulting data sample (after combining table rows and filtering them). So adding where and join operators will not change the essence.
Let's imagine an abstract example. Let's say you have a summary table of forum users. Let's call it userstat and it looks like this. An important point, we believe that a user can only belong to one group.
user_name - user name
forum_group - group name
mess_count - number of messages
is_have_social_profile - whether the forum profile contains a link to a page on a social network
As you can see, the table is simple and you can calculate many things yourself using a calculator. However, this is just an example and there are only 10 entries. In real databases, records can be measured in thousands. So let's start with the queries.
Pure grouping using group by
Let's imagine that we need to know the value of each group, namely the average rating of users in the group and the total number of messages left in the forum.
First, a short verbal description to make it easier to understand the SQL query. So, you need to find the calculated values by forum groups. Accordingly, you need to divide all these ten lines into three different groups: admin, moder, user. To do this, you need to add a grouping by the values of the forum_group field at the end of the request. And also add calculated expressions to select using so-called aggregate functions.
Specify fields and calculated columns select forum_group, avg(raiting) as avg_raiting, sum(mess_count) as total_mess_count -- Specify the table from userstat -- Specify grouping by field group by forum_group
Please note that after you have used the group by construct in a query, you can use only those fields in the select that were specified after the group by without using aggregate functions. The remaining fields must be specified inside aggregate functions.
I also used two aggregate functions. AVG - calculates the average value. And SUM - calculates the sum.
| forum_group | avg_rating | total_mess_count |
|---|---|---|
| admin | 4 | 50 |
| moder | 3 | 50 |
| user | 3 | 150 |
1. First, all rows of the source table were divided into three groups according to the values of the forum_group field. For example, there were three users within the admin group. There are also 3 lines inside moder. And inside the user group there were 4 lines (four users).
2. Aggregate functions were then applied to each group. For example, for the admin group the average rating was calculated as follows (2 + 5 + 5)/3 = 4. The number of messages was calculated as (10 + 15 + 25) = 50.
As you can see, nothing complicated. However, we applied only one grouping condition and did not filter by group. So let's move on to the next example.
Grouping using group by and filtering groups with having
Now, let's look at a more complex example of data grouping. Let’s say we need to evaluate the effectiveness of actions to attract users to social activities. To put it simply, find out how many users in groups left links to their profiles, and how many ignored mailings, etc. However, in real life there may be many such groups, so we need to filter out those groups that can be neglected (for example, too few people did not leave a link; why clutter up the full report). In my example, these are groups with only one user.
First, we will verbally describe what needs to be done in the SQL query. We need to divide all the rows of the original userstat table according to the following criteria: group name and the presence of a social profile. Accordingly, it is necessary to group the table data by the forum_group and is_have_social_profile fields. However, we are not interested in those groups where there is only one person. Therefore, such groups need to be filtered out.
Note: It is worth knowing that this problem could be solved by grouping by only one field. If you use the case construct. However, within the framework of this example, the possibilities of grouping are shown.
I would also like to immediately clarify one important point. You can filter using having only when using aggregate functions, and not by individual fields. In other words, this is not a where construct, it is a filter for groups of rows, not individual records. Although the conditions inside are specified in a similar way using "or" and "and".
This is what the SQL query would look like
Specify fields and calculated columns select forum_group, is_have_social_profile, count(*) as total -- Specify the table from userstat -- Specify grouping by fields group by forum_group, is_have_social_profile -- Specify the group filter having count(*) > 1
Please note that the fields after the group by construct are separated by commas. Specifying fields in select occurs in the same way as in the previous example. I also used the aggregate function count, which calculates the number of rows in groups.
Here's the result:
| forum_group | is_have_social_profile | total |
|---|---|---|
| admin | 1 | 2 |
| moder | 1 | 2 |
| user | 0 | 3 |
Let's take a step-by-step look at how this result turned out.
1. Initially, 6 groups were obtained. Each of the forum_group groups was divided into two subgroups based on the values of the is_have_social_profile field. In other words, groups: , , , , , .
Note: By the way, there would not necessarily be 6 groups. So, for example, if all administrators filled out a profile, then there would be 5 groups, since the is_have_social_profile field would have only one value for users of the admin group.
2. Then the filter condition in having was applied to each group. Therefore, the following groups were excluded: , , . Since within each such group there was only one row of the source table.
3. After this, the necessary data was calculated and the result was obtained.
As you can see, there is nothing difficult to use.
It is worth knowing that depending on the database, the capabilities of these constructs may differ. For example, there may be more aggregate functions, or you can specify calculated columns rather than individual fields as a grouping. This information must already be looked at in the specification.
Now, you know how to group data with group by, as well as how to filter groups using having.

If there is a section in the table expression GROUP BY SQL, then the following is executed GROUP BY.
If we denote by R the table that is the result of the previous section ( FROM or WHERE), then the result of the section GROUP BY is a partition of R into a set of row groups consisting of the minimum number of groups such that for each column from the list of columns of the section GROUP BY in all rows of each group containing more than one row, the values of this column are equal. To indicate the result of a section GROUP BY the standard uses the term “ grouped table”.
If the statement SELECT contains a sentence GROUP BY(SELECT GROUP BY), the selection list can only contain the following expression types:
- Constants.
- Aggregate functions.
- Functions USER, UID, and SYSDATE.
- Expressions, corresponding to those listed in the proposal GROUP BY.
- Expressions, including the above expressions.
Example 1. Calculate the total purchase volume for each product:
SELECT stock, SUM( quant) FROM ordsale GROUP BY stock;
Phrase GROUP BY does not involve string ordering. To organize the result of this example by product codes, you should place the phrase ORDER BY stock after the phrase GROUP BY.
Example 2. You can use data groupings GROUP BY together with the condition. For example, for each product purchased, select its code and the total volume of purchases, with the exception of customer purchases with code 23:
SELECT stock, SUM( quant) FROM ordsale WHERE customerno<>23 GROUP BY stock;
Lines that do not satisfy the condition WHERE, are excluded before grouping the data.
Table rows can be grouped by any combination of its fields. If the field whose values are used to group contains any undefined values, then each of them generates a separate group.
Let's say there is a task to calculate the quantity of a product. The supplier supplies us with products at a certain price. Let's calculate the total quantity of each product. The GROUP BY phrase will help us with this. The result of the task will be a table consisting of several columns. Deliveries will be grouped by PR. The layout occurs in groups, which is initiated by Group By SQL. It should be noted that this phrase assumes the use of the Select phrase, which in turn defines a single value for each expression of the formed group. There are three cases for a given expression: it takes an arithmetic value, it becomes an SQL function that will reduce all the values in a column to a sum or other specified value, or the expression can become a constant. Table rows do not have to be strictly grouped; they can be grouped by any combination of table columns. It must be taken into account that ordering requests by PR is possible if an appropriate request is made.
Translates a SELECT query into an internal execution plan (“query plan”), which can differ even for syntactically identical queries and from a specific DBMS.
The SELECT statement consists of several clauses (sections):
- SELECT defines a list of returned columns (both existing and calculated), their names, restrictions on the uniqueness of rows in the returned set, restrictions on the number of rows in the returned set;
- FROM specifies a table expression that defines the underlying data set for applying the operations defined in other statement clauses;
- WHERE specifies a restriction on the rows of the table expression from the FROM clause;
- GROUP BY combines series that have the same property using aggregate functions
- HAVING selects among the groups defined by the GROUP BY parameter
- ORDER BY specifies row sorting criteria; the sorted rows are passed to the call point.
Statement structure
The SELECT statement has the following structure:
SELECT [ DISTINCT | DISTINCTROW | ALL ] select_expression ,... FROM table_references [ WHERE where_definition ] [ GROUP BY ( unsigned_integer | col_name | formula ) ] [ HAVING where_definition ] [ ORDER BY ( unsigned_integer | col_name | formula ) [ ASC | DESC ], ...]
Operator Options
ORDER BY
ORDER BY - optional (optional) operator parameter SELECT and UNION , which means that the operators SELECT, UNION return a set of rows sorted by the values of one or more columns. It can be applied to both numeric and string columns. In the latter case, sorting will occur alphabetically.
Using the ORDER BY clause is the only way to sort the result set of rows. Without this clause, the DBMS may return rows in any order. If ordering is necessary, ORDER BY must be present in SELECT , UNION .
Sorting can be done either in ascending or descending order of values.
- The ASC option (default) sets the sort order in ascending order, from smallest to largest values.
- The DESC parameter sets the sort order in descending order, from largest values to smallest values.
Examples
SELECT * FROM T ;
| C1 | C2 |
|---|---|
| 1 | a |
| 2 | b |
| C1 | C2 |
|---|---|
| 1 | a |
| 2 | b |
SELECT C1 FROM T ;
| C1 |
|---|
| 1 |
| 2 |
| C1 | C2 |
|---|---|
| 1 | a |
| 2 | b |
| C1 | C2 |
|---|---|
| 1 | a |
| C1 | C2 |
|---|---|
| 1 | a |
| 2 | b |
| C1 | C2 |
|---|---|
| 2 | b |
| 1 | a |
For table T query
SELECT * FROM T ;
will return all columns of all rows of the given table. For the same table query
SELECT C1 FROM T ;
will return the values of column C1 of all rows of the table - in terms of relational algebra projection. For the same table query
will return the values of all columns of all rows of the table for which the value of field C1 is equal to "1" - in terms of relational algebra we can say that the sample, since the WHERE keyword is present. Last request
SELECT * FROM T ORDER BY C1 DESC ;
will return the same rows as the first one, however the result will be sorted in reverse order (Z-A) due to the use of the ORDER BY keyword with field C1 as the sort field. This query does not contain the WHERE keyword, so it will return everything in the table. Multiple ORDER BY elements can be specified separated by commas [eg. ORDER BY C1 ASC, C2 DESC] for more precise sorting.
Selects all rows where the column_name field is equal to one of the listed values value1,value2,...
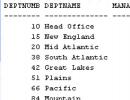
Returns a list of department IDs that had sales greater than $1,000 on January 1, 2000, along with the sales amounts for that day:
Limiting the rows returned
According to ISO SQL:2003, the returned data set can be limited using:
- introduction window functions into the SELECT statement
Window function ROW_NUMBER()
There are various window functions. ROW_NUMBER() OVER can be used to simple limitation number of rows returned. For example, to return no more than ten rows:
ROW_NUMBER can be non-deterministic: if key is not unique; each time a query is executed, it is possible to assign different numbers to rows that have key matches. When key unique, each line will always receive a unique line number.
Window function RANK()
The RANK() OVER function works almost the same as ROW_NUMBER, but can return more than n lines under certain conditions. For example, to get the top 10 youngest people:
This code can return more than 10 lines. For example, if there are two people with the same age, it will return 11 rows.
Non-standard syntax
Not all DBMSs support the above window functions. However, many have non-standard syntax for solving the same problems. Below are the options simple limitation samples for various DBMSs:
| Manufacturer/DBMS | Constraint syntax |
|---|---|
| DB2 | (Supports standard starting with DB2 Version 6) |