Можно ли прибраться на компе раз и навсегда? Использование сохранённого поиска в качестве отправной точки.
«Пора бы прибраться на своем компе...» Думаю, эта мысль возникала у всех пользователей, и не раз. Без приборки любой комп рано или поздно превращается в свалку хлама, и найти нужные файлы становится все труднее. Даже если вырабатывается какая-то система каталогизации и хранения, новые интересы могут потребовать новых инструментов и новых иерархий. А если машин несколько или на одной машине уживаются несколько пользователей, все становится еще сложнее.
Я, конечно, пытался использовать какие-то методы сортировки помимо файловой системы - т.к. часто хочется упорядочить файлы не по одному критерию, а по нескольким равнозначным, что невозможно сделать в древовидной иерархии - требуется сетевая структура. Но все мои усилия разбивались об интерфейс. Судите сами.
PersonalBrain
(www.thebrain.com)
Довольно хорошая утилита для организации файлов, папок и url-ссылок. Минусы: платная, довольно медленная (Java-based), нельзя пометить тегом сразу большую группу объектов. Плюсы: есть возможность переключать виды (облако, дерево, таблица).
Утилита для пометки файлов тегами и поиска по ним. Минусы: работает только под Windows, трудно пометить тегом сотни файлов.
Файловая система, основанная на тегах. Минусы: работает только под Linux, используется тот же интерфейс, что и для древовидной структуры. Плюсы: верный выбор места, где должны использоваться теги - организация виртуальной файловой системы.
Другая проблема, дополняющая данную - это желание иметь версионирование в файловой системе. Я пользуюсь git с 2009 года, и все прекрасно, за исключением того, что git работает поверх той же древовидной файловой системы. Если мы вводим теговую организацию, естественно было бы включить туда и версионирование.
Чего бы хотелось
1. При попадании любого файла на комп (в том числе при установке программ, распаковке архивов и пр.) он автоматически помечается следующими тегами:
- откуда скачан (урл, локальный путь с указанием имени компьютера, откуда он был скачан, либо имя данного компьютера, если он был создан на нем с нуля, плюс ссылка на оригинальный файл и его версию, если это копия или версия другого файла)
- дата создания (когда скачан, timestamp)
- дата обновления=дата создания
- полное имя файла (в кодировке UTF-8)
- MIME-тип файла
- человеческое название MIME-типа (музыка, программа, видео)
- размер файла
Данная метаинформация обладает версионностью.
2. Пользователь может в любой момент добавить к файлу любое кол-во других тегов, изменить и удалить их. Удалить и изменить автоматические теги вручную нельзя. При добавлении-изменении-удалении тегов существуют два варианта сохранения, см.ниже.
3. При создании, изменении и сохранении любого файла (и метаинформации) существуют два варианта сохранения:
3.1 Сохранение мелкой правки файла: содержимое, размер файла и дата обновления перезаписываются. Сохранение мелкой правки метаинформации: добавление-изменение-удаление тегов без сохранения истории.
3.2 Полное сохранение (коммит) файла: создается новая версия файла и метаинформации. Полное сохранение (коммит) метаинформации: создается ее новая версия.
Выбор варианта сохранения - два хоткея, например: F2 - Save, Shift+F2 - Commit. При нажатии любого из них всплывает строка ввода, в которую можно ввести теги через запятую (в первом случае - это просто теги (которые могут, конечно, состоять из нескольких слов), в случае commit это будет commit-сообщение). Эти же операции можно осуществлять с группой файлов.
4. При отсутствии критерия поиска вид по умолчанию - дерево, в котором файлы упорядочены по следующему списку критериев-тегов: человеческое название MIME-типа, дата обновления, полное имя файла. Данный список можно редактировать: менять порядок тегов, добавлять и удалять теги из списка автоматических. Можно создавать новые списки тегов и сохранять их как виды. Деревом же можно пользоваться так же, как обычной файловой системой - заходить и выходить из «папок»-тегов, сортировать файлы. Например, создание папки и перенос туда файлов будет означать создание пользовательского тега и присвоение его файлам.
5. Поиск по умолчанию ведется только среди последних версий метаинформации. Интерфейс поиска состоит из двух панелей: на одной находится набор контролов для фильтрации поиска по стандартным атрибутам (дата создания, обновления, человеческое название MIME-типа, размер от, размер до), на другой - строка ввода (ищет и по стандартным, и по пользовательским атрибутам, также ищет по частям тегов, есть автокомплит).
6. Результаты поиска показываются в виде таблицы файлов с колонками: версия метаданных-версия файла-имя-размер-человеческое название MIME-типа-дата создания-дата обновления-откуда скачан-пользовательские теги/commit-сообщение. Порядок колонок можно менять, нажатием на заголовок колонки можно сортировать вывод по данной колонке. Внизу выводится общее количество файлов и время, затраченное на поиск. Поисковые запросы можно сохранять и использовать позже.
7. Для каждого файла из контекстного меню доступны команды «посмотреть историю метаинформации», «посмотреть историю файла», «получить версию файла» (при этом на полученный файл распространяются все критерии выше, что позволяет построить граф копий и версий одного файла)
8. При покидании компа (или удалении файла) метаинформация и содержимое файла удаляются вместе со всей историей.
Этапы достижения идеального
Виртуальная файловая система с реализацией файлового менеджера под нее и git-like версионностью - дело непростое. Для начала можно просто попробовать сделать надстройку-демон, реализующую описанные функции и работающую поверх существующих файлосистем (NTFS, ext3/4). Нужно также поставить git и положить в него весь жесткий диск. Далее демон отслеживает
- появление всех новых файлов, помечая их автотегами и добавляя в git
- перенос, модификацию и удаление файлов, обновляя информацию в базе-хранилище и в git
- отвечает на запросы к базе, выдавая результаты
Плюс интерфейс поиска/файловый менеджер, хотя бы в виде плагинов к total commander/FAR/Nautilus/mc (да простят меня поклонники макоси за то, что я не пользуюсь их системой).
Да, я забыл упомянуть Google Desktop [почивший 14 сентября 2011, googledesktop.blogspot.com/2011/09/google-desktop-update.html ], а также Copernic Desktop Search и прочие en.wikipedia.org/wiki/Desktop_search) Почему? Во-первых, они ищут еще и в файлах (контент внутри файлов), что не требовалось. Во-вторых, версионность в этих движках отсутствует. Справедливости ради все же замечу, что в них реализована часть из описанного мной функционала, поэтому рассмотрение данных движков имеет смысл - возможно, я сделаю это в последующих статьях.
P.S. Кстати, есть предположение (того же Гугла), что вскоре все будут мигрировать в веб и в облака, поэтому десктоп-поисковики маст дай. Насчет этого я не согласен: человеку нужно иметь private place и контроль над информацией без доступа посторонних, как бы Гуглу ни хотелось знать все обо всех. Да и в торренты вряд ли кто-то будет когда-нибудь выкладывать абсолютно все. Так что у десктоп-поиска с версионностью есть будущее.
Для профессионального поиска в Интернете необходимы специализированный софт, а также специализированные поисковики и поисковые сервисы.
ПРОГРАММЫ
http://dr-watson.wix.com/home – программа предназначена для исследования массивов текстовой информации с целью выявления сущностей и связей между ними. Результат работы – отчет об исследуемом объекте.
http://www.fmsasg.com/ - одна из лучших в мире программ по визуализации связей и отношений Sentinel Vizualizer . Компания полностью русифицировала свои продукты и подключил горячую линию на русском.
http://www.newprosoft.com/ – “Web Content Extractor” является наиболее мощным, простым в использовании ПО извлечения данных из web сайтов. Имеет также эффективный Visual Web паук.
SiteSputnik – не имеющий в мире аналогов программный комплекс, позволяющий вести поиск и обработку его результатов в Видимом и Невидимом Интернете, используя все необходимые пользователю поисковики.
WebSite-Watcher – позволяет проводить мониторинг веб-страниц, включая защищенные паролем, мониторинг форумов, RSS каналов, групп новостей, локальных файлов. Обладает мощной системой фильтров. Мониторинг ведется автоматически и поставляется в удобном для пользователя виде. Программа с расширенными функциями стоит 50 евро. Постоянно обновляется.
http://www.scribd.com/ – наиболее популярная в мире и все более широко применяемая в России платформа размещения различного рода документов, книг и т.п. для свободного доступа с очень удобным поисковиком по названиям, темам и т.п.
http://www.atlasti.com/ – представляет собой самый мощный и эффективный из доступных для индивидуальных пользователей, небольшого и даже среднего бизнеса инструмент качественного анализа информации. Программа многофункциональная и потому полезная. Совмещает в себе возможности создания единой информационной среды для работы с различными текстовыми, табличными, аудио и видеофайлами, как единым целым, а также инструменты качественного анализа и визуализации.
Ashampoo ClipFinder HD – все возрастающая доля информационного потока приходится на видео. Соответственно, конкурентным разведчикам нужны инструменты, позволяющие работать с этим форматом. Одним из таких продуктов является представляемая бесплатная утилита. Она позволяет осуществлять поиск роликов по заданным критериям на видеофайловых хранилищах типа YouTube. Программа проста в использовании, выводит на одну страницу все результаты поиска с подробными сведениями, названиями, длительностью, временем, когда видео было загружено в хранилище и т.п. Имеется русский интерфейс.
http://www.advego.ru/plagiatus/ – программа сделана seo оптимизаторами, но вполне подходит как инструмент интернет-разведки. Плагиатус показывает степень уникальности текста, источники текста, процент совпадения текста. Также программа проверяет уникальность указанного URL. Программа бесплатная.
http://neiron.ru/toolbar/ – включает надстройку для объединения поиска Google и Yandex, а также позволяет осуществлять конкурентный анализ, базирующийся на оценке эффективности сайтов и контекстной рекламы. Реализован как плагин для FF и GC.
http://web-data-extractor.net/ – универсальное решение для получения любых данных, доступных в интернете. Настройка вырезания данных с любой страницы производится в несколько кликов мыши. Вам нужно просто выбрать область данных, которую вы хотите сохранять и Datacol сам подберет формулу для вырезания этого блока.
CaptureSaver – профессиональный инструмент исследования интернета. Просто незаменимая рабочая программа, позволяющая захватывать, хранить и экспортировать любую интернет информацию, включая не только web страницы, блоги, но и RSS новости, электронную почту, изображения и многое другое. Обладает широчайшим функционалом, интуитивно понятным интерфейсом и смешной ценой.
http://www.orbiscope.net/en/software.html – система веб мониторинга по более чем доступным ценам.
http://www.kbcrawl.co.uk/ – программное обеспечение для работы, в том числе в «Невидимом интернете».
http://www.copernic.com/en/products/agent/index.html – программа позволяет вести поиск, используя более 90 поисковых систем, более чем по 10 параметрам. Позволяет объединять результаты, устранять дубликаты, блокировать нерабочие ссылки, показывать наиболее релевантные результаты. Поставляется в бесплатной, личной и профессиональной версиях. Используется больше чем 20 млн.пользователей.
Maltego – принципиально новое программное обеспечение, позволяющее устанавливать взаимосвязь субъектов, событий и объектов в реале и в интернете.
СЕРВИСЫ
new – эффективный поисковик-агрегатор для поиска людей в основных российских социальных сетях.
https://hunter.io/ – эффективный сервис для обнаружения и проверки email.
https://www.whatruns.com/ – простой в использовании, но эффективный сканер, позволяющий обнаружить, что работает и не работает на веб-сайте и каковы дыры в безопасности. Реализован также как плагин к Chrom.
https://www.crayon.co/ – американская бюджетная платформа рыночной и конкурентной разведки в интернете.
http://www.cs.cornell.edu/~bwong/octant/ – определитель хостов.
https://iplogger.ru/ – простой и удобный сервис для определения чужого IP .
http://linkurio.us/ – новый мощный продукт для работников экономической безопасности и расследователей коррупции. Обрабатывает и визуализирует огромные массивы неструктурированной информации из финансовых источников.
http://www.intelsuite.com/en – англоязычная онлайн платформа для конкурентной разведки и мониторинга.
http://yewno.com/about/ – первая действующая система перевода информации в знания и визуализации неструктурированной информации. В настоящее время поддерживает английский, французский, немецкий, испанский и португальский языки.
https://start.avalancheonline.ru/landing/?next=%2F – прогнозно-аналитические сервисы Андрея Масаловича.
https://www.outwit.com/products/hub/ – полный набор автономных программ для профессиональной работы в web 1.
https://github.com/search?q=user%3Acmlh+maltego – расширения для Maltego.
http://www.whoishostingthis.com/ – поисковик по хостингу, IP адресам и т.п.
http ://appfollow .ru / – анализ приложений на основе отзывов, ASO оптимизации, позиций в топах и поисковых выдачах для App Store , Google Play и Windows Phone Store .
http://spiraldb.com/ – сервис, реализованный как плагин к Chrom , позволяющий получить множество ценной информации о любом электронном ресурсе.
https://millie.northernlight.com/dashboard.php?id=93 - бесплатный сервис, собирающий и структурирующий ключевую информацию по отраслям и компаниям. Есть возможность использования информационных панелей основанных на текстовом анализе.
http://byratino.info/ – сбор фактографических данных из общедоступных источников в сети Интернет.
http://www.datafox.co/ – CI платформа собирающая и анализирующая информацию по интересующим клиентов компаниям. Есть демо.
https://unwiredlabs.com/home - специализированное приложение с API для поиска по геолокации любого устройства, подключенного к интернету.
http://visualping.io/ – сервис мониторинга сайтов и в первую очередь имеющихся на них фотографий и изображений. Даже если фотография появилась на секунду, она будет в электронной почте подписчика. Имеет плагин для G oogleC hrome.
http://spyonweb.com/ – исследовательский инструмент, позволяющий осуществить глубокий анализ любого интернет-ресурса.
http://bigvisor.ru/ – сервис позволяет отслеживать рекламные компании по определенным сегментам товаров и услуг, либо конкретным организациям.
http://www.itsec.pro/2013/09/microsoft-word.html – инструкция Артема Агеева по использованию программ Windows для нужд конкурентной разведки.
http://granoproject.org/ – инструмент с открытым исходным кодом для исследователей, которые отслеживают сети связей между персонами и организациями в политике, экономике, криминале и т.п. Позволяет соединять, анализировать и визуализировать сведения, полученные из различных источников, а также показывать существенные связи.
http://imgops.com/ – сервис извлечения метаданных из графических файлов и работы с ними.
http://sergeybelove.ru/tools/one-button-scan/ – маленький он-лайн сканер для проверки дыр безопасности сайтов и других ресурсов.
http://isce-library.net/epi.aspx – сервис поиска первоисточников по фрагменту текста на английском языке
https://www.rivaliq.com/ – эффективный инструмент для ведения конкурентной разведки на западных, в первую очередь, европейских и американских рынках товаров и услуг.
http://watchthatpage.com/ – сервис, который позволяет автоматически собирать новую информацию с поставленных на мониторинг ресурсов в интернете. Услуги сервиса бесплатные.
http://falcon.io/ – своего рода Rapportive для Web. Он не является заменой Rapportive, а дает дополнительные инструменты. В отличие от Rapportive дает общий профиль человека, как бы склеенный из данных из социальных сетей и упоминаний в web.http://watchthatpage.com/ – сервис, который позволяет автоматически собирать новую информацию с поставленных на мониторинг ресурсов в интернете. Услуги сервиса бесплатные.
https://addons.mozilla.org/ru/firefox/addon/update-scanner/ – дополнение для Firefox. Следит за обновлениями web-страниц. Полезно для web-сайтов, которые не имеют лент новостей (Atom или RSS).
http://agregator.pro/ – агрегатор новостных и медийных порталов. Используется маркетологами, аналитиками и т.п. для анализа новостных потоков по тем или иным темам.
http://price.apishops.com/ – автоматизированный веб-сервис мониторинга цен по выбранным товарным группам, конкретным интернет-магазинам и другим параметрам.
http://www.la0.ru/ – удобный и релевантный сервис анализа ссылок и бэклинков на интернет-ресурс.
www.recordedfuture.com – мощный инструмент анализа данных и их визуализации, реализованный как он-лайн сервис, построенный на «облачных» вычислениях.
http://advse.ru/ – сервис под слоганом «Узнай все про своих конкурентов». Позволяет в соответствии с поисковыми запросами получить сайты конкурентов, анализировать рекламные компании конкурентов в Google и Yandex.
http://spyonweb.com/ – сервис позволяет определить сайты с одинаковыми характеристиками, в том числе, использующими одинаковые идентификаторы сервиса статистики Google Analytics, IP адреса и т.п.
http://www.connotate.com/solutions – линейка продуктов для конкурентной разведки, управления информационными потоками и преобразования сведений в информационные активы. Включает как сложные платформы, так и простые дешевые сервисы, позволяющие эффективно вести мониторинг вместе с компрессией информации и получением только нужных результатов.
http://www.clearci.com/ – платформа конкурентной разведки для бизнеса различных размеров от стартапов и маленьких компаний до компаний из списка Fortune 500. Решена как saas.
http://startingpage.com/ – надстройка на Google, позволяющая вести поиск в Google без фиксации вашего IP адреса. Полностью поддерживает все поисковые возможности Google, в том числе и а русском языке.
http://newspapermap.com/ – уникальный сервис, очень полезный для конкурентного разведчика. Соединяет геолокацию с поисковиком он-лайн медиа. Т.е. вы выбираете интересующий вас регион или даже город, или язык, на карте видите место и список он-лайн версий газет и журналов, нажимаете на соответствующую кнопку и читаете. Поддерживает русский язык, очень удобный интерфейс.
http://infostream.com.ua/ – очень удобная отличающаяся первоклассной выборкой, вполне доступная для любого кошелька система мониторинга новостей «Инфострим» от одного из классиков интернет-поиска Д.В.Ландэ.
http://www.instapaper.com/ – очень простой и эффективный инструмент для сохранения необходимых веб-страниц. Может использоваться на компьютерах, айфонах, айпадах и др.
http://screen-scraper.com/ – позволяет автоматически извлекать всю информацию с веб-страниц, скачивать подавляющее большинство форматов файлов, автоматически вводить данные в различные формы. Скачанные файлы и страницы сохраняет в базах данных, выполняет множество других чрезвычайно полезных функций. Работает под всеми основными платформами, имеет полнофункциональную бесплатную и очень мощные профессиональные версии.
http://www.mozenda.com/- имеющий несколько тарифных планов и доступный даже для малого бизнеса веб сервис многофункционального веб мониторинга и доставки с избранных сайтов необходимой пользователю информации.
http://www.recipdonor.com/ - сервис позволяет осуществлять автоматический мониторинг всего происходящего на сайтах конкурентов.
http://www.spyfu.com/ – а это, если у вас конкуренты иностранные.
www.webground.su – созданный профессионалами Интернет-поиска сервис для мониторинга Рунета, включающий всех основных поставщиков информации, новостей и т.п., способен к индивидуальным настройкам мониторинга под нужды пользователя.
ПОИСКОВИКИ
https ://www .idmarch .org / – лучший по качеству выдачи поисковик мирового архива pdf документов. В настоящее время проиндексировано более 18 млн. pdf документов, начиная от книг, заканчивая секретными отчетами.
http://www.marketvisual.com/ – уникальный поисковик, позволяющий вести поиск собственников и топ-менеджмента по ФИО, наименованию компании, занимаемой позиции или их комбинации. В поисковой выдаче содержатся не только искомые объекты, но и их связи. Рассчитана прежде всего на англоязычные страны.
http://worldc.am/ – поисковик по фотографиям в свободном доступе с привязкой к геолокации.
https://app.echosec.net/ – общедоступный поисковик, который характеризует себя как самый продвинутый аналитический инструмент для правоохранительных органов и профессионалов безопасности и разведки. Позволяет вести поиск фотографий, размещенных на различных сайтах, социальных платформах и в социальных сетях в привязке к конкретным геолокационным координатам. В настоящее время подключено семь источников данных. До конца года их число составит более 450. За наводку спасибо Дементию.
http://www.quandl.com/ – поисковик по семи миллионам финансовых, экономических и социальных баз данных.
http://bitzakaz.ru/ – поисковик по тендерам и госзаказам с дополнительными платными функциями
Website-Finder – дает возможность найти сайты, которые плохо индексирует Google. Единственным ограничением является то, что для каждого ключевого слова он ищет только 30 веб-сайтов. Программа проста в использовании.
http://www.dtsearch.com/ – мощнейший поисковик, позволяющий обрабатывать терабайты текста. Работает на рабочем столе, в интернете и в интранете. Поддерживает как статические, так и динамические данные. Позволяет искать во всех программах MS Office. Поиск ведется по фразам, словам, тегам, индексам и многому другому. Единственная доступная система федеративного поиска. Имеет как платную, так и бесплатную версии.
http://www.strategator.com/ – осуществляет поиск, фильтрацию и агрегацию информации о компании из десятка тысяч веб-источников. Ищет по США, Великобритании, основным странам ЕЭС. Отличается высокой релевантностью, удобностью для пользователя, имеет бесплатные и платный вариант (14$ в месяц).
http://www.shodanhq.com/ – необычный поисковик. Сразу после появления получил кличку «Гугл для хакеров». Ищет не страницы, а определяет IP адреса, типы роутеров, компьютеров, серверов и рабочих станций, размещенных по тому или иному адресу, прослеживает цепочки DNS серверов и позволяет реализовать много других интересных функций для конкурентной разведки.
http://search.usa.gov/ – поисковик по сайтам и открытым базам всех государственных учреждений США. В базах находится много практической полезной информации, в том числе и для использования в нашей стране.
http://visual.ly/ – сегодня все шире для представления данных используется визуализация. Это первый поисковик инфографики в Вебе. Одновременно с поисковиком на портале есть мощные инструменты визуализации данных, не требующие навыков программирования.
http://go.mail.ru/realtime –поиск по обсуждениям тем, событий, объектов, субъектов в режиме реального, либо настраиваемого времени. Ранее крайне критикуемый поиск в Mail.ru работает очень эффективно и дает интересную релевантную выдачу.
Zanran – только что стартовавший, но уже отлично работающий первый и единственный поисковик для данных, извлекающий их из файлов PDF, таблиц EXCEL, данных на страницах HTML.
http://www.ciradar.com/Competitive-Analysis.aspx – одна из лучших в мире систем поиска информации для конкурентной разведки в «глубоком вебе». Извлекает практически все виды файлов во всех форматах по интересующей теме. Реализована как веб-сервис. Цены более чем приемлемые.
http://public.ru/ – Эффективный поиск и профессиональный анализ информации, архив СМИ с 1990 года. Интернет-библиотека СМИ предлагает широкий спектр информационных услуг: от доступа к электронным архивам публикаций русскоязычных СМИ и готовых тематических обзоров прессы до индивидуального мониторинга и эксклюзивных аналитических исследований, выполненных по материалам печати.
Cluuz – молодой поисковик с широкими возможностями для конкурентной разведки, особенно, в англоязычном интернете. Позволяет не только находить, но и визуализировать, устанавливать связи между людьми, компаниями, доменами, e-mail, адресами и т.п.
www.wolframalpha.com – поисковик завтрашнего дня. На поисковый запрос выдает имеющуюся по объекту запроса статистическую и фактологическую информацию, в том числе, визуализированную.
www.ist-budget.ru – универсальный поиск по базам данных госзакупок, торгов, аукционов и т.п.
Каждый день мы что-то ищем в Google. Я, наверное, раз 200 в день что-нибудь ищу в Google. Я проверяю любую информацию, узнаю что-то новое, моментально нахожу ответ на свой вопрос. Возник вопрос - вбил в поисковую строку - получил результат. Что может быть проще? Но иногда возникают трудности при поиске конкретной информации. Несколько трюков помогут вам всегда находить искомое.
Мы уже не раз писали о секретах поиска в Google. Я решил проверить, какие трюки работают до сих пор, и немного освежить их в вашей памяти.
Поиск конкретной фразы
Иногда бывает необходимо найти фразу именно в том виде, в котором мы её вводим. Например, когда мы ищем текст песни, но знаем только одну фразу из неё. В таком случае вам нужно заключить эту фразу в кавычки.
Поиск по конкретному сайту
Google - отличный поисковик. И часто он лучше, чем встроенный поиск на сайтах. Именно поэтому рациональнее использовать Google для поиска информации на каком-нибудь сайте. Для этого вводим site:lenta.ru Путин сделал .

Поиск слов в тексте
Если вам нужно, чтобы в тексте найденных результатов были все слова запроса, введите перед ним allintext: .

Если одно слово запроса должно быть в тексте, а остальные - в любом другом месте страницы, включая заголовок или URL, поставьте перед словом intext: , а остальное напишите до этого.

Поиск слов в заголовке
Если вы хотите, чтобы все слова запроса были в заголовке, используйте фразу allintitle: .

Если только часть запроса должна быть в заголовке, а остальное - в другом месте документа или страницы, ставьте intitle:
.
Поиск слов в URL
Чтобы найти страницы, у которых ваш запрос прописан в URL, введите allinurl: .

Поиск новостей для конкретной локации
Если вам нужны новости по определённой тематике из конкретной локации, используйте location: для поиска по новостям Google.

Поиск с каким-то количеством пропущенных слов
Вам нужно найти предложение в документе или в статье, но вы помните только слова в начале и в конце. Введите свой запрос и укажите, сколько приблизительно слов было между теми словами, которые вы помните. Выглядит это так: «У лукоморья AROUND(5) дубе том».

Поиск, если забыли какое-то слово или цифру
Забыли какое-то слово из поговорки, песни, цитаты? Не беда. Google всё равно поможет его найти. Поставьте звёздочку (*) на месте забытого слова.

Поиск сайтов, которые ссылаются на интересующий вас сайт
Этот пункт полезен владельцам блогов или сайтов. Если вам интересно, кто же ссылается на ваш сайт или даже на определённую станицу, то достаточно ввести link:сайт .
Исключить результаты с ненужным словом
Представим ситуацию. Вы решили поехать отдыхать на острова. И вы совсем не хотите на Мальдивы. Чтобы Google не показывал их в результатах поиска, нужно просто ввести «Отдых на островах −Мальдивы». То есть перед словом Мальдивы поставить минус.

Вы желаете найти всех своих конкурентов. Или вам очень нравится сайт, но не хватает материала на нём, а вам хочется ещё и ещё. Вводим related:lenta.ru и любуемся результатом.

Поиск «или-или»
Бывают ситуации, когда вам нужно найти информацию, касающуюся двух людей сразу. Например, вы хотите посмеяться над Вовой, но не решили, над каким - Зеленским или ещё каким-нибудь. Достаточно ввести «Владимир Зеленский|Жириновский», и вы получите нужный вам результат. Вместо символа «|» можно вводить английское OR.

Поиск разных слов в одном предложении
Для нахождения связей между объектами или просто для поиска упоминания двух личностей вместе можно использовать символ «&». Пример: «Фрейд & Юнг».

Поиск по синонимам
Если вы такой же ленивый, как и я, то вам не хватает терпения гуглить несколько раз по разным синонимам одного слова. Например, дешёвые дрова. Символ «~» может значительно упростить вам жизнь. Пишем «~дешёвые дрова» и получаем результаты по словам «дешёвый», «недорогой», «доступный» и так далее.

Поиск в определённом диапазоне чисел
Очень полезный секрет поиска в Google, если вам нужно найти, например, события, которые произошли в определённые года, или цены в определённом диапазоне. Просто поставьте две точки между числами. Google будет искать в этом диапазоне.

Поиск файлов определённого формата
Если вам нужно найти какой-нибудь документ или просто файл определённого формата, то и здесь вам может помочь Google. Достаточно добавить в конце вашего запроса filetype:doc и вместо doc подставить нужный вам формат.

Ещё 10 полезных функций
1. Google может поработать неплохим калькулятором. Для этого просто введите нужную операцию в поисковую строку.

2. Если вы хотите узнать значение слова, а не просто посмотреть страницы по теме, добавляйте к слову define или «значение».
3. Можно использовать поисковик в качестве конвертера величин и валют. Чтобы вызвать конвертер, наберите запрос с переводом, например, «сантиметры в метры».

4. С помощью Google вы можете узнать погоду и время без необходимости заходить на сайты. Наберите запросы «погода „интересующий город“», «время „интересующий город“».
5. Чтобы посмотреть результаты и расписание матчей спортивной команды, просто наберите в поисковике её название.

6. Чтобы перевести слово на любой язык, напишите в поисковой строке «перевести „нужное слово“ на английский (любой другой) язык».
7. По запросу «восход „интересующий город“» Google показывает время восхода и заката (для последнего - соответствующий запрос).

8. cache:site.com - очень выручающая иногда функция поиска сайта в кеше Google. Например, когда новостники удаляют новости. Их можно прочитать благодаря Google.
9. Если вы вводите в поисковую строку номер авиарейса, Google выдаёт полную информацию о нём.

10. Чтобы увидеть таблицу с котировками конкретной компании, просто введите запрос «акции „интересующая компания“», например «Акции Apple».

Если у вас есть свои способы эффективнее использовать Google и быстрее находить нужную информацию, делитесь советами в комментариях к этой статье.
13.04.2007 Джон Сэвилл
По умолчанию окно поиска в проводнике ищет в текущей папке и всех вложенных папках любые файлы, в имени или метаданных которых содержится заданное слово, либо файлы определенных типов, содержащие искомое слово собственно в данных
В. Какие теги можно использовать для поиска в проводнике Windows?
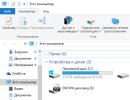
О. . Например, на рисунке по адресу http://list.windowsitpro.com/t?ctl=512BB:BDF92CD301AFA7F9401757564AC5299D показано, что первый файл содержит совпадение в метаданных, второй файл (misc.one) содержит ключевое слово в тексте файла, а другие совпали только по имени.
Получив результаты поиска, можно нажать кнопку Search Tools и выбрать пункт Search Pane для доступа к панели инструментов для фильтрации результатов по типу (например, все файлы, электронная почта, документ, изображение, музыка). Также имеется режим Advanced Search, в котором открывается большее по размеру окно критерия для детального поиска. Например, можно искать только теги для "Superman"; в этом случае сравнение проводится только по тегам файла и будет получен только один результат.
Чтобы не проводить расширенный поиск каждый раз, можно указать в поле нужный тип поиска. Например, чтобы искать только файлы, в имени которых есть слово "Superman", можно ввести name:superman.
То же самое можно сделать и с другими критериями:
- Автор документа -
- Имя документа - name:
- Теги метаданных - tag:(); например, tag:(superman)
- Файлы, измененные после даты - modified:>date; например, modified:>3/2/2007
- Дата файла - date:
- Создание файла - Datecreated:
- Размер, Кбайт - Size:>number (> больше чем, = равно,
Самый простой способ выбрать оптимальный критерий - выполнить расширенный поиск и запомнить генерируемый критерий поиска, а затем поместить критерий поиска в поле поиска.
> Как скачать ID3 тэги из Интернета?
Вступление.
Если вы храните коллекцию МР3 музыки (или любых других форматов: FLAC, APE и так далее), то наверняка среди файлов есть такие, у которых не заполнены поля ID3 тэгов или названия которых имеют неинформативный вид типа "track01.mp3". Как исправить ситуацию и заполнить тэги для красивого отображения при проигрывании? Вручную заполнять их - не выход, это может занять месяцы. Здесь нам поможет программа, способная найти и скачать ID3 тэги из Интернета , mp3Tag Pro .
Шаг первый: Загрузка и установка программы.
Загрузите mp3Tag Pro в выбранную папку и запустите установку. Следуйте инструкциям инсталляции для завершения процесса.
Шаг второй: Запуск программы. Выбор аудио-файлов для редактирования.
Запустите установленную программу. При помощи дерева папок слева найдите директорию, где хранятся аудио-файлы, требующие редактирования тэгов. Также это можно сделать при помощи кнопки "Обзор" в строке адреса папки.
Выберите все аудио в текущей папке при помощи кнопки "Выбрать все" и нажмите "Генерировать" под списком файлов.

Из выпадающего меню выберите "Получить тэги из FreeDB".
Шаг третий: Получение тэгов из FreeDB. Сохранение информации.
Откроется новое окно. В нем, на вкладке "FreeDB", нажмите "Получить альбом". В выпадающем списке результатов поиска выберите подходящий вариант альбома.

Программа автоматически загрузит ID3 тэги с интернета , и они появятся в списке превью. Если все тэги заполнились правильно, то нажмите "Сохранить альбом" в самом низу окна, и они пропишутся в файлы альбома. После этого вы всегда будете знать имя исполнителя, название альбома и самой песни для каждой композиции.
После сохранения можно нажать на кнопку "Переименовать", появившуюся вместо "Сохранить альбом". Это позволит изменить имена файлов с использованием только что полученной информации из тэгов - например, по шаблону "Исполнитель - название песни". Шаблон задается в левом верхнем углу окна.